What does it take to understand a black hole, those amazing astronomical features at the center of every galaxy, including our Milky Way? A lot of complex computational science done on supercomputers by researchers like Professor Jim Stone at Princeton University. Dr. Stone is Chair of Princeton’s Astrophysics Department. He is also director of the Princeton Institute for Computational Science and Engineering, or PICSciE (pronounced pik-see) and is a professor in both the Astrophysics Department and in the Program in Applied and Computational Mathematics (PACM).
Understanding Plasmas with Supercomputers
“One of the areas of focus in my research is black holes,” said Dr. Stone. “I’m mostly interested in astrophysical gas dynamics and computational fluid dynamics (CFDs) for astrophysical plasmas, because most of the visible matter that you can see in astrophysical systems is a plasma. Stars, galaxies, and interstellar media are plasmas. If you want to understand their dynamics and structure and be able to interpret images from telescopes, you have to model the gas, magnetic field, radiation transport and other physics in the flows. We do that using thousands of cores on big supercomputers.”
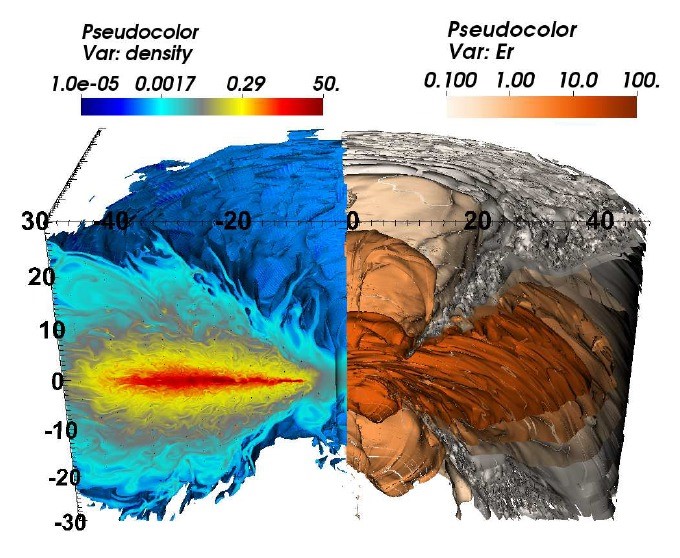
Snapshot of the global structure of a radiation-dominated accretion flow onto a black hole. The left side of the image shows the mass density, and the right the radiation energy density. A very complex, turbulent flow is evident, driven by MHD processes. Such simulations are used to interpret astronomical observations of black holes, such as active galactic nuclei.
MHD is magnetohydrodynamics, which is an extension of fluid dynamics. Plasmas are electrically conducting fluids, so they respond to magnetic fields. But they are also affected by photons, so radiation transport also impacts their dynamics and structures. “That’s one substantial difference between modeling astrophysical plasmas and modeling terrestrial flows, like water or airplanes in flight. You don’t need to worry about these things in terrestrial flows. Incorporating MHDs and radiation transport increases the complexity of our systems of equations by about an order of magnitude beyond terrestrial flows,” added Stone. All these properties are modeled in 3D space over time in complex systems of partial differential equations (PDEs), which generate as much as 100 TBs of data for analysis and visualization. “We’ve been running our computational models on about 250,000 cores on a supercomputer at Argonne National Laboratory,” added Stone.
Over his career, Professor Stone has seen the evolution of computational science and software engineering for astrophysics go from large vector processor machines, to x86 clusters, to vector units in CPUs and now to large vector processing engines again like the Intel® Xeon Phi™ processor (formerly codenamed Knights Landing). “Our codes have evolved over the last 20 years along with the CPU architectures. In the last two years, we’ve completely rewritten our programs from scratch to take advantage of vector processing in the x86 architecture.” That’s where his students in PACM and Ian Cosden of Princeton come in to help make those new codes perform up to four times faster than they have to date thanks to some clever optimizations with Intel® Advanced Vector Extensions 512 (Intel® AVX512) and the Intel Xeon Phi processor.
Optimizing for Many Integrated Core
Ian is a performance tuning analyst at Princeton University. “I help the scientists, who are experts in their own domains improve the efficiency of the codes they use for their projects. I don’t work on the codes per se. I’m more of a consultant to the programmers.”
Dr. Cosden created a testing code that he uses to run on new processors as they appear on the market. “It’s a hand-optimized, highly vectorized and parallelized benchmark code of a physics Nbody algorithm and mimics the kinds of work we see from the scientists here at Princeton,” stated Cosden.
After getting a baseline performance on his Broadwell architecture-based, two-socket Intel® Xeon® processor E5 v4 family workstation, he re-ran it on the single-node Intel® Xeon Phi™ processor card in the workstation.
“It ran 2.5x faster on Intel Xeon Phi—that’s with only changing a single optimization switch for cache utilization. Essentially that performance gain was purely from recompiling for Intel AVX512 and running it on the Intel Xeon Phi processor after optimizing it for the x86 CPU,” he added.
Part of Cosden’s work is to evangelize to the researchers and computational scientists writing the code that there is incredible value in tuning and optimization.
“I use my benchmark code in various workshops to illustrate the importance of investing time to make their code more efficient for the architecture it’s going to run on,” he added.
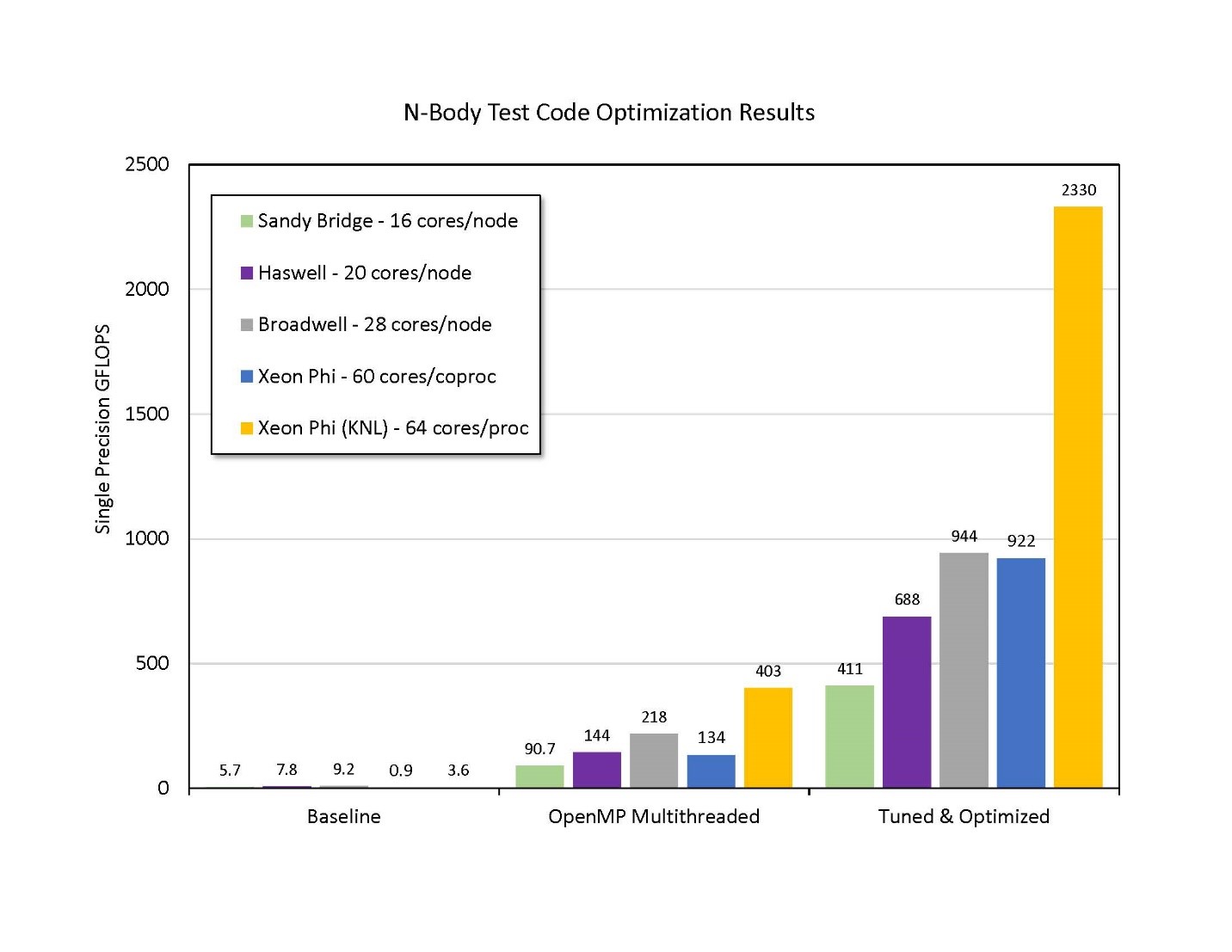
In his workshops at Princeton, Cosden shows the scientists what can happen when you take unoptimized code, parallelize it with simple tools, then optimize it for maximum efficiency on x86-based architectures like the Intel Xeon processors and Intel Xeon Phi processors. In the workshop, he first shows a 3.6 GFLOPS baseline performance using unoptimized, non-parallelized code running on a single core on x86.
“Then, I show what happens when we run it through the Intel® compiler and do the best we can simply with compiler flags to optimize and vectorize it.” That ran 9.2 GFLOPS on Broadwell and 3.6 GFLOPS on Knights Landing. “Finally, after parallelizing the code and using some optimization and tuning tricks to maximize the efficiency, I could achieve 944 GFLOPS on Broadwell. But when I turn Knights Landing loose on it, I get 2.3 TFLOPS. The bar charts make it very compelling. And the scientists quickly get the importance of the investment.”
MIC—the Future of Computational Science
Dr. Cosden believes that there is a future for processing big jobs using many integrated core (MIC) architectures like Intel Xeon Phi processor in multiple nodes on a single server or cluster. Scientists can design and optimize their codes on x86-based workstations, and immediately run them on Intel Xeon Phi processor-based clusters without additional—or very little—work.
“I actually optimized my benchmark code for x86 on an Ivy Bridge architecture-based system, then moved it to the Broadwell-based machine, then to a single Intel Xeon Phi processor card.” The beauty, pointed out Cosden, is that the optimization work done on the “CPU,” the Intel Xeon processor, can immediately run on the “MIC,” the Intel Xeon Phi processor node.
There’s no paradigm shift to run on the new architecture. “I show the students in my workshop, that, because they invest in tuning their programs, they immediately get the benefit of the larger number of cores in big clusters with MIC nodes like the Intel Xeon Phi processor cards. And they can take their codes to any Intel architecture-based cluster, with or without MIC nodes—or share their codes in the community. The performance benefit is portable, because the code is portable.”
“I developed my benchmark specifically to maximize multithreaded, vectorized code performance on Intel® architecture,” added Cosden. “When working with the scientists, it provides a reference of what can be done if we fully optimize their codes. It doesn’t mean we can get there; it depends on the problem being solved. But it provides a good reference of what the architecture can do and how to go about making improvements.”
“Some of my PACM students,” stated Professor Stone, “have been doing fundamental work in numerical analysis trying to understand how to discretize the equations in our algorithms and solve them on a computer,” commented Stone. While Stone and his team worked on the algorithms and software, Cosden worked in parallel, providing guidance on how to optimize the codes for the Intel architecture. “He and I iterated many times,” commented Stone, “to figure out the most efficient way to set up the memory and set up the instructions for running the vector extensions. And that led to a complete redesign and rewrite of our code to make it more efficient and to be able to work well on these new emerging architectures. That was a very important step, because it enabled us to make the code run faster and do things we couldn’t do before.”
“Jim and his students provided the science and algorithm development,” added Cosden, “and I only helped with tuning, how to design efficient data structures, and how to structure the code to take full advantage of the vector registers.”
“We’re now getting about 15 to 20 percent of peak efficiency of an Intel CPU with our codes, which is pretty good for us,” said Stone. “Our code runs four times faster using Intel AVX512 than it used to.” The entire code is too big to run on Cosden’s testbed workstation or their small four-node cluster with Intel Xeon Phi processors. “But, we can take it directly to Knights Landing when a cluster is available. We expect a very significant speedup in our codes compared to what we’re running on now,” stated Stone.
For Dr. Stone that means he can do a lot more science than before, run much more detailed models of the flows he’s researching, and add more physics to his models. “Most of the calculations done in astrophysics don’t include important things that we think are dominating the flow, like radiation transport. It’s too computationally expensive, so we use simple models to try to understand how the problem behaves. But with more computing capacity and by optimizing the codes, we can add as much physics as possible and study things more realistically. Our goal is that, if we have all the physics, we’re better able to reproduce the observations exactly, or we can identify what we’re not understanding. The real reward for the hard work in redesigning and optimizing the code is to try to get as much physics in as possible,” concluded Stone.
Optimizing the Science
Dr. Stone pointed out that Princeton is very fortunate to have the resources of a performance tuning analyst available. “Scientists today have to know how to write code, they have to know how to do high-performance computing, but they aren’t experts in tuning, which is important to maximize the computational science being done,” he said.
“Jim and the Princeton administrators are seeing the value of having additional software engineers to assist the domain specialists,” added Cosden. “I think it’s very forward looking and will benefit Princeton greatly over time to have these kinds of human resources available. We can help bridge the gaps between the new architectures and the domain specialists to advance and accelerate computational research on campus,” he concluded.


