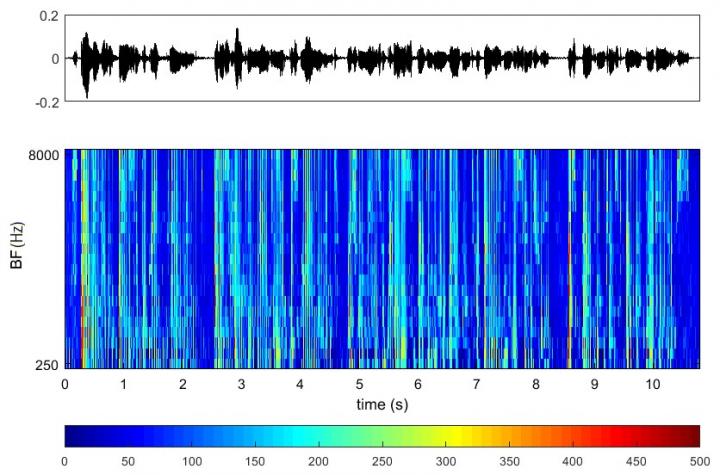
Speech signal and its transformation into the reaction of the auditory nerve. Credit: Peter the Great St.Petersburg Polytechnic University
Russian scientists have come closer to creating a digital system to process speech in real-life sound environment, for example, when several people talk simultaneously during a conversation. Researchers of Peter the Great St. Petersburg Polytechnic University (SPbPU), a Project 5-100 participant, have simulated the process of the sensory sounds coding by modelling the mammalian auditory periphery. The current results of this study were published in a scientific article “Semi-supervised Classifying of Modelled Auditory Nerve Patterns for Vowel Stimuli with Additive Noise”.
According to the SPbPU experts, the human nervous system processes information in the form of neural responses. The peripheral nervous system, which involves analyzers (particularly visual and auditory) provide perception of the external environment. They are responsible for the initial transformation of external stimuli into the neural activity stream and peripheral nerves ensure that this stream reaches to the highest levels of the central nervous system. This lets a person qualitatively recognize the voice of a speaker in an extremely noisy environment. At the same time, according to researchers, existing speech processing systems are not effective enough and require powerful computational resources.
To solve this problem, the research was conducted by the experts of the ‘Measuring information technologies department at SPbPU. The study is funded by the Russian Foundation for Basic Research . During the study, the researchers developed methods for acoustic signal recognition based on peripheral coding. Scientists will partially reproduce the processes performed by the nervous system while processing information and integrate this process into a decision-making module, which determines the type of the incoming signal.
“The main goal is to give the machine human-like hearing, to achieve the corresponding level of machine perception of acoustic signals in the real-life environment,” said the project lead Anton Yakovenko. According to Yakovenko, the examples of the responses to vowel phonemes given by the auditory nerve model created by the scientists are represented the source dataset. Data processing was carried out by a special algorithm, which conducted structural analysis to identify the neural activity patterns the model used to recognize each phoneme. The proposed approach combines self-organizing neural networks and graph theory. According to the scientists, analysis of the reaction of the auditory nerve fibers allowed to identify vowel phonemes correclty under significant noise exposure and surpassed the most common methods for parameterization of acoustic signals. The SPbPU researchers believe that the methods developed should help create a new generation of neurocomputer interfaces, as well as ‘ provide better human-machine interaction. In this regard, this study has a great potential for practical application: in cochlear implantation (surgical restoration of hearing), separation of sound sources, creation of new bioinspired approaches for speech processing, recognition and computational auditory scene analysis based the machine hearing principles.
“The algorithms for processing and analysing big data implemented within the research framework are universal and can be implemented to solve the tasks that are not related to acoustic signal processing,” said Anton Yakovenko. He added that one of the proposed methods was successfully applied for the network behavior anomaly detection.