Discovering information in unstructured data is a major research topic today because it underlies everything from web-search engines to finding recommendations for movies and restaurants. At the University of Texas at Austin, Dr. Keshav Pingali, the W.A. “Tex” Moncrief Chair of Grid and Distributed Computing, leads a team of scientists who use supercomputers at the Texas Advanced Computing Center (TACC) to extract insights from a particular kind of unstructured data called graphs.
“An airline route map is an example of a graph,” Pingali said. “A route map has cities and it shows which pairs of cities are connected by direct flights. In the same way, a general graph has nodes, and pairs of nodes are connected by edges. Some of the biggest graphs we deal with come from web-crawls, and they may have tens of billions of nodes and trillions of edges. Supercomputers like the ones we have at TACC are essential for processing graphs of this size.”
Working with Professor Vijaya Ramachandran’s group in the University of Texas Computer Science department, Pingali and his team invented a new distributed-memory parallel algorithm for computing a graph property called betweenness-centrality. Their paper, which was published at the ACM Symposium on Principles and Practice of Parallel Programming (PPoPP), was awarded three Artifact Evaluation badges by the PPoPP organizing committee because the committee was able to successfully run their code on the Stampede2 supercomputer at TACC and reproduce the results reported in the paper. Grigori Fursin, PPoPP 2019 Artifact Evaluation (AE) co-chair, wrote, “This experience will be very useful – it’s the first time in my AE experience when we had to validate results on a supercomputer.”
How betweenness-centrality (BC) finds important nodes in graphs
The goal of BC is to assign a score to each node in the graph; the higher the BC score, the more important the node. While importance can be defined in many ways, BC scores are computed by considering the shortest paths between each pair of nodes in the graph. Nodes with a high BC value are contained in a larger fraction of these shortest paths than nodes with a low BC value.
“Almost all airlines use the hub and spoke model to organize flights,” states Loc Hoang, a graduate student in Pingali’s group and first author on the paper. “If you look at route maps such as the one shown in Figure 1, you will immediately recognize the hubs because they are the cities through which lots of passengers must travel even if that is not their destination. The goal of BC computation is to identify such important nodes automatically in graphs that cannot be visualized because they have billions of nodes.”
Researchers previously used BC to identify disease carriers in epidemics, to analyze power grids for single points of failure, and to determine influencers in social networks such as terrorist networks.
Figure 1 .Airline route map (from Global Support Initiative).
Stampede2 supercomputer powers BC research
The team performs most of their BC runs on TACC’s Stampede2 cluster. Stampede2 is powered by Intel Xeon Scalable processors, and each machine has 48 2.1 GHz cores on 2 sockets (24 cores per socket) and 192GB RAM [1]. The machines are connected through Intel Omni-Path Architecture. Stampede2 is one of the most powerful and significant current supercomputers in the U.S. for open science research. The team hopes to continue their research on TACC’s future supercomputer named Frontera which will be based on 2nd Generation Intel Xeon Scalable processors.
“The benefit of computing BC on a distributed cluster like Stampede2 is that you have more computational power and more memory. Our research gives users a distributed algorithm called Min-Rounds BC (MRBC) that is provably communication-efficient and returns results to users faster,” states Pingali.
The team implemented the MRBC algorithm in D-Galois, the open source distributed graph analytics system named after the French mathematician Evariste Galois, which runs on clusters like Stampede2. To aid in developing MRBC, the team used Intel VTune software to debug performance issues.
“We also used the Intel Omni-Path architecture on Stampede2 because we believe it improves communication across the machines in the supercomputer, resulting in a better runtime for all code that uses it,” states Hoang.
Performance of the MRBC algorithm
Pingali’s team used up to 256 machines on Stampede2 to compute approximate BC scores for power-law graphs and road networks. Compared to the BC algorithm of Brandes (denoted by SBBC in the charts), MRBC reduces the number of communication rounds by 14.0x and the communication time by 2.9x on the average for graphs in the test suite. Figure 2 shows the strong scaling of execution time for two such large graphs, gsh15 and clueweb12. These results are for computing an approximation of BC: calculation of exact BC values would take even more time, so MRBC would save even more time than shown in the figure.
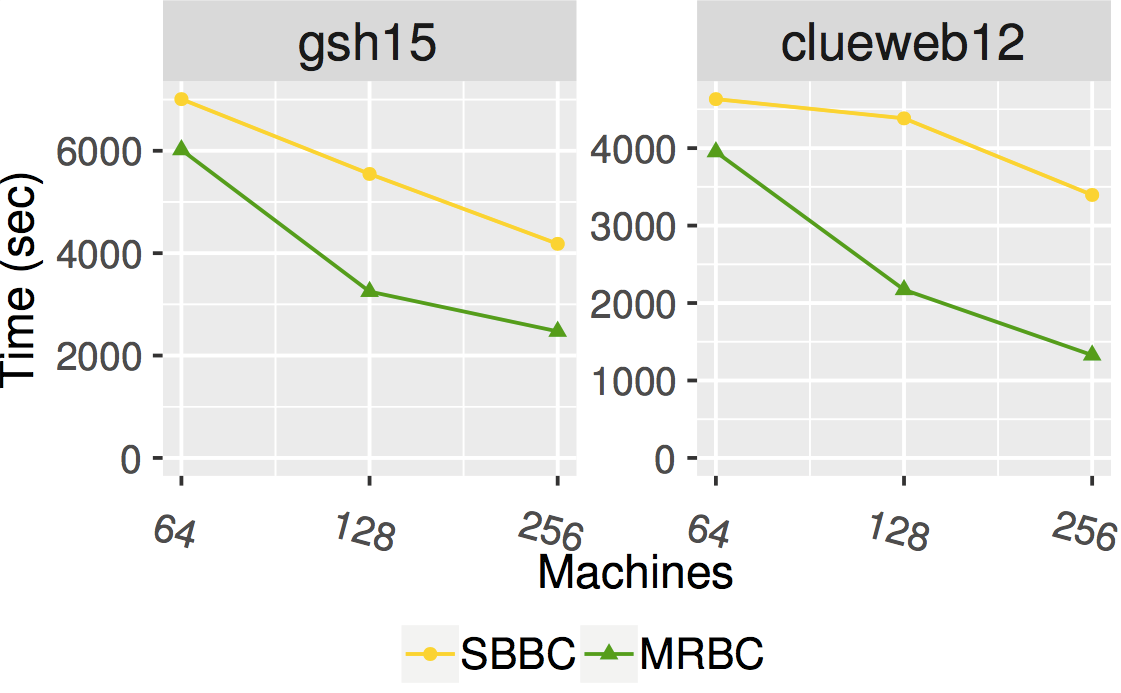
Figure 2. Execution times of two BC algorithms [Courtesy of Dr. Keshav Pingali, University of Texas at Austin].
Conclusion
“Having a supercomputer like Stampede2 has made a big difference to us since we can run compute-intensive and data-intensive algorithms like MRBC in a small fraction of the time that would be required on a small cluster,” said Pingali. “Also, there are disruptive memory technologies like Intel Optane DC persistent memory and new processor designs coming soon in the new Frontera system which makes this an exciting time to be working in HPC!”
Linda Barney is the founder and owner of Barney and Associates, a technical/marketing writing, training and web design firm in Beaverton, OR.
This article was produced as part of Intel’s HPC editorial program, with the goal of highlighting cutting-edge science, research and innovation driven by the HPC community through advanced technology. The publisher of the content has final editing rights and determines what articles are published.


