[Adobe Stock]
This is why CAS emphasizes curating “fit-for-purpose” data, which includes uncovering the lessons from negative results in failed experiments and processing scientific knowledge from more than 50 languages. CAS has been collecting and indexing chemical information for over a century.
“We also use advanced tech and AI within CAS to curate this information, but humans are still in the equation,” Dennis said.
AI augments what our scientists (most Ph.D. level) do because it can’t yet provide the level of quality our partners demand in science.

Michael W. Dennis, Ph.D.
CAS’s approach is to pair domain scientists with algorithmic “muscle” and its century-old catalog. The CAS Content Collection covers hundreds of millions of compounds, reactions and biomarkers, each mapped to a controlled ontology that collapses naming chaos. “Scientists haven’t harmonized around a language,” Dennis said. “For polyethylene glycol, we might have 10,000 different names in the database.”
The organization maps it to a CAS Registry Number, an identifier that connects it all, but it doesn’t discard the other names. “We do this for small molecules, proteins, genes, diseases, organisms,” Dennis refers to the technique as “very precise,” offering a “controlled vocabulary that connects disparate data.”
Such detailed data curation highlights a hard-won lesson in the AI journey. A decade ago, the emphasis was often squarely on the algorithms, with less appreciation for the foundational role of comprehensive, well-structured information. This oversight meant that important dataset aspects, like the inherent biases or gaps, were not always addressed upfront.
This challenge is acute in scientific research, where “most researchers publish when an experiment worked, but don’t tend to publish when the experiment failed,” Dennis noted. While CAS maintains some negative data from failed experiments, “there’s not as much of that out there in the world at the moment.”
The “Triangle of Success”
And the verticals CAS serves, including pharma, oil and gas, consumer goods, cosmetics, and specialty chem, AI weaves through all of them. But the focus has changed over the years. “A decade ago the focus was on the tech solving all problems, structuring unstructured information. It didn’t quite work,” Dennis said. “Today, organizations understand you need highly reliable, structured data. We call it the ‘Triangle of Success'” In other words, subject matter experts, advanced tech (algorithms, foundational models), and curated and structured scientific data. “That’s where we come in,” Dennis said. “Many organizations, including major tech companies, are reaching out for access to this information.
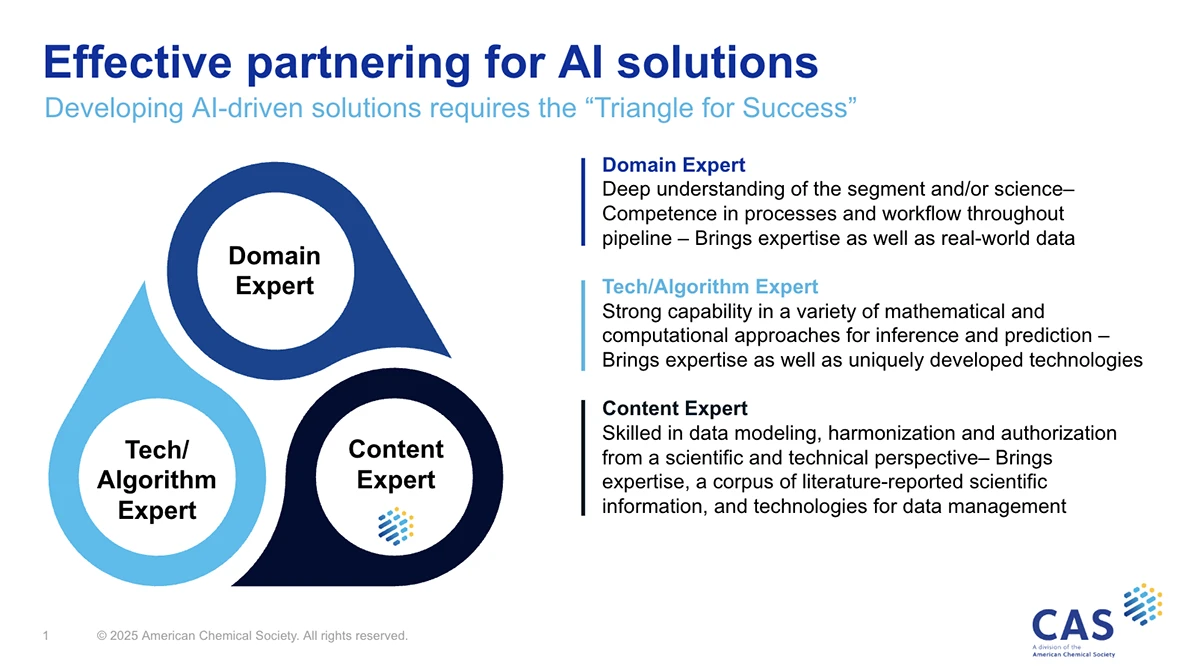
Triangle of Success diagram [Image from CAS]
In drug discovery, Dennis says some partnerships have identified drug candidates that are now moving through clinical trials. “Those candidates were identified using that triangle, using that advanced tech, those subject matter experts and our content,” he said. The approach extends beyond pharmaceuticals: CAS is helping one large company use AI to predict alternatives for a water-soluble film they’re concerned might face regulation. The collaboration is considering factors from application requirements to sustainability. In another case, a chemical company developing electronic devices partnered with CAS for custom datasets to train its models. That work has the organization to be “first to market” with a unique device.
In another partnership, ChemLex, an AI-driven contract research organization, needed high-quality data to train their Regio-MPNN model for predicting regioselectivity in chemical reactions. Open-access data proved insufficient and imbalanced. Working with CAS, the firm received a curated dataset that significantly improved their model’s accuracy, “outperforming senior organic chemists and previous model architectures,” according to a CAS case study.
Similarly, Selvita, one of Europe’s largest preclinical CROs, needed machine learning datasets to optimize parallel synthesis workflows. CAS delivered verified datasets containing 400,000 entries for Suzuki reactions and 200,000 for amide coupling reactions within days. When tested against a senior chemist, the resulting model identified optimal conditions in hours that took the chemist over a week to determine.
The skills challenge
A recipe for success in data science has been the synthesis of domain expertise with software and math chops. A growing number of younger researchers have expertise in both. “We call them the ‘triple threat.’” Dennis said. “They are so much more powerful. The earlier-career folks we’re hiring often have a Ph.D. in, say, biochemistry, plus informatics/bioinformatics experience. They embrace data. They know how to code. They’re the most valuable, though somewhat unicorns — not always easy to find,” he said
Market signals back him up. While the U.S. Bureau of Labor Statistics reports median chemist salaries at $84,150, professionals combining domain expertise with computational skills command significant premiums. Computational chemists average about $126,706, according to PayScale while bioinformatics engineers make roughly $131,053 on average, according to ZipRecruiter.
Until universities churn out more of these hybrids, firms face a choice: poach, pay up, or retrain their existing talent to speak, say, both SMILES strings and Python. But while your chemists learn to code — or your data scientist learns to understand chemical nomenclature, don’t forget about data quality.