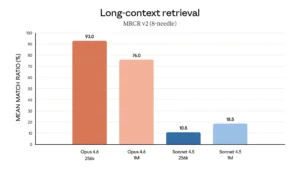
Anthropic-reported long-context retrieval scores.
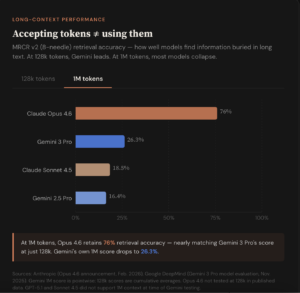
Anthropic has dropped a new model. Opus 4.6, which can now ingest roughly 750,000 words of text in a single session and, more importantly, actually use that context without the performance degradation that has plagued earlier models. Claude Opus 4.6, released February 5, scored 76% on a long-context retrieval benchmark where its predecessor managed just 18.5%. Anthropic calls the gap the company calls “a qualitative shift” in usable context.
The distinction matters for researchers accustomed to working with large code bases and large document sets: patent portfolios, regulatory submissions, literature reviews. In all of these cases, earlier AI models would progressively lose the thread as input grew. A million tokens translates to roughly 10-15 full-length journal articles or a substantial regulatory filing processed in a single pass, without the need to chunk documents or summarize content mid-analysis.
Opus 4.6 is the first of Anthropic’s top-tier Opus models to offer a 1M-token context window, currently in beta. On the MRCR v2 benchmark, a needle-in-a-haystack test that buries multiple pieces of information across vast amounts of text, the model scored 76% on the hardest variant: eight needles hidden across one million tokens. Its predecessor, Claude Sonnet 4.5, scored 18.5% on the same test. The problem the benchmark measures, known in the field as “context rot,” has been a persistent limitation: model performance degrades as conversations or document inputs exceed a certain length, effectively shrinking the usable window well below its advertised size.
That framing puts Anthropic in direct conversation with Google, whose Gemini models have offered 1M-token context windows since 2024 (and in some cases 2M). But advertised capacity and usable performance are increasingly divergent metrics. Google reports Gemini 3 Pro scoring 77% on MRCR v2 at 128,000 tokens. That is roughly in line with Opus 4.6’s score. At the actual 1M-token mark, however, Gemini 3 Pro’s score drops to 26.3%, according to Google’s own model evaluation card published at its November 2025 launch. Developer forums have echoed the gap: users of various Gemini models have reported significant performance degradation after using as little as 15–20% of the advertised context window, with Reddit complaints surfacing as recently as late January 2026 about Gemini 3 Pro losing recall after 32,000 tokens.
Caveats apply. Anthropic’s 76% figure is self-reported and awaits independent verification. Google’s 26.3% dates to the Gemini 3 Pro launch in November and may improve with the production non-preview version of Gemini 3 Pro. The MRCR v2 benchmark itself has evolved. Google has shifted to a harder 8-needle variant, making older scores difficult to compare directly with newer ones.
Knowledge work gains
Beyond long-context performance, Opus 4.6 claims state-of-the-art scores across several evaluations relevant to knowledge-intensive work. On GDPval-AA, an independently administered evaluation of economically valuable knowledge work spanning finance, legal and other professional domains, Opus 4.6 outperformed OpenAI’s GPT-5.2 by approximately 144 Elo points and its own predecessor, Opus 4.5, by 190 points. Anthropic says the Elo gap translates to Opus 4.6 obtaining a higher score than GPT-5.2 roughly 70% of the time on that evaluation.
 The model also reportedly leads all currently released frontier models on Humanity’s Last Exam, a complex multidisciplinary reasoning test, though Anthropic’s methodology merits a footnote. The company ran Opus 4.6 with web search, code execution, programmatic tool calling, and up to 3M tokens of total context enabled, a substantially augmented setup compared to a standard model evaluation. In agentic coding, the model scored 65.4% on Terminal-Bench 2.0, ahead of GPT-5.2’s 64.7% and Gemini 3 Pro’s 56.2%. On BrowseComp, which measures a model’s ability to locate hard-to-find information online through multi-step search, Opus 4.6 again leads the field. Its score of 68.8% on ARC-AGI-2, a benchmark designed around problems that are easy for humans but difficult for AI — represents a notable jump from Opus 4.5’s 37.6%.
The model also reportedly leads all currently released frontier models on Humanity’s Last Exam, a complex multidisciplinary reasoning test, though Anthropic’s methodology merits a footnote. The company ran Opus 4.6 with web search, code execution, programmatic tool calling, and up to 3M tokens of total context enabled, a substantially augmented setup compared to a standard model evaluation. In agentic coding, the model scored 65.4% on Terminal-Bench 2.0, ahead of GPT-5.2’s 64.7% and Gemini 3 Pro’s 56.2%. On BrowseComp, which measures a model’s ability to locate hard-to-find information online through multi-step search, Opus 4.6 again leads the field. Its score of 68.8% on ARC-AGI-2, a benchmark designed around problems that are easy for humans but difficult for AI — represents a notable jump from Opus 4.5’s 37.6%.
| Benchmark | What it tests | Opus 4.6 | Opus 4.5 | Sonnet 4.5 |
|---|---|---|---|---|
| BioPipelineBench | Bioinformatics workflows: sequence analysis, metagenome assembly, chromatin profiling | 53.1% | 28.5% | 19.3% |
| BioMysteryBench | Computational + biological reasoning from raw datasets (e.g., identifying knocked-out genes) | 61.5%* | 48.8% | 34.7% |
| Structural Biology (MC) | Biomolecular structure-function relationships, multiple choice | 88.3% | 81.7% | 70.9% |
| Structural Biology (open) | Same, open-ended format | 28.4% | 21.2% | 17.9% |
| Organic Chemistry | Spectroscopy, synthetic route design, SMILES/IUPAC conversion | 53.9% | 48.6% | 31.2% |
| Phylogenetics | Evolutionary relationship analysis, tree structure reasoning | 61.3% | 42.1% | 33.8% |
*Surpassed human expert baseline. All benchmarks developed internally by Anthropic; not publicly released. Models tested with code execution tools, without extended thinking. Source: Anthropic system card, Feb. 2026.
For R&D audiences, the life sciences performance may be the most directly relevant benchmark. Anthropic says Opus 4.6 performs almost twice as well as its predecessor on industry benchmarks for computational biology, structural biology, organic chemistry and phylogenetics — a claim the company made in direct outreach to trade press but did not detail with specific scores in its public announcement.
Early third-party testing supports the claim in at least one applied setting. Justin Reppert, a machine learning research engineer at Elicit, a research tool used in scientific literature analysis, reported that “Claude Opus 4.6 achieved 85% recall on our biopharma competitive intelligence benchmark—a 12-point lift over baseline (p<0.02; 100% Bayesian probability of improvement)—through autonomous 15-minute discovery loops with zero prompt tuning. On the hardest tasks, the improvement exceeded 30 points. For users who need to find every competitor, not just the obvious ones, this lift makes a critical difference.”