New, many-core scalability results delivered a best paper award to NWChem researchers from Lawrence Berkeley National Laboratory (LBNL) and Pacific Northwest National Laboratory (PNNL) at the latest Intel Xeon Phi User’s Group (IXPUG).
“Our achievement is especially good news for researchers who use NWChem because it means that they can exploit multicore architectures of current and future supercomputers in an efficient way,” says Mathias Jacquelin a scientist in the Computational Research Division (CRD) at Berkeley Lab.
Importance of the work
The team believes that strong scaling is key to simulating mesoscale (e.g. longer-term) phenomena, an important capability for computational chemists. If one assumes it takes a computer one second to compute a time step, they say, then a 100 picosecond simulation (one hundred trillionths of a second) would take around 10-15 days of simulation time. Observing phenomena that occur over timespans as long as one nanosecond (one billionth of a second) would require 100 to 150 days of simulation time (Source IXPUG NWChem presentation).
On the basis of this latest work, the team believes the AIMD kernel in NWChem can scale to O(1k) Intel Xeon Phi processors. This is an important result both for computational chemists as well as other HPC scientists.
More precisely, the AIMD kernel contains three major hotspots that exhibit different performance behavior:
- A calculation that involves computing a large number of 3D FFTs (required when applying VH and Vxc)
- Performing a large number of tall-and-skinny matrix operations to calculate the non-local pseudopotentials.
- Enforcing orthogonality, which also performs a number of tall-and-skinny matrix multiplications.
Exploiting multicore architectures
NWChem is a widely used open-source software suite that has been developed over the past 20 years to solve challenging chemical and biological problems using large-scale parallel algorithms based on first principle calculations. These calculations provide useful solutions to problems in chemistry and materials science. According to Bert de Jong, a computational chemist in the Computational Research Division (CRD) at Berkeley Lab, these solutions, “Allow us to look at the structure, coordination, reactions and thermodynamics of complex dynamical chemical processes in solutions and on surfaces”. An example image is shown below.
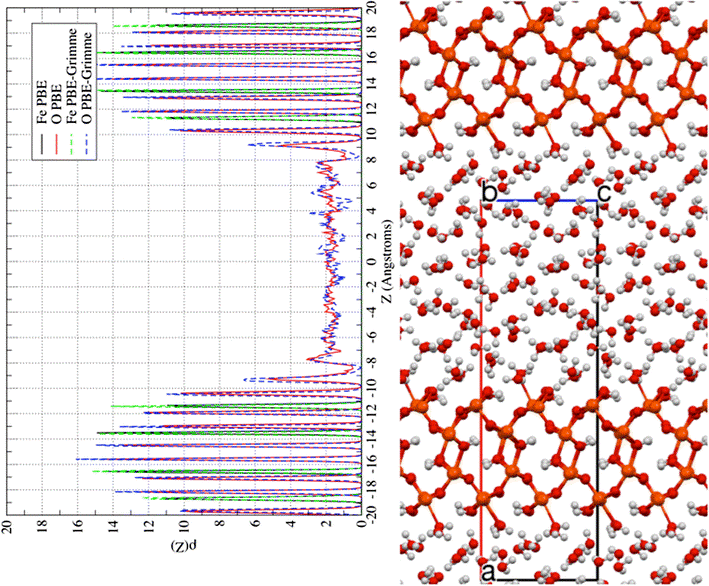
Figure 1: Laterally averaged oxygen atom and iron atom densities from DFT AIMD simulations for the 100 surface of goethite. From Chen, Y.; Bylaska, E. J.; Weare, J. H. Weakly Bound Water Structure, Bond Valence Saturation and Water Dynamics at the Goethite (100).
Given the lengthy approximately 20 year lifespan of NWChem, this software suite has had to be adapted to a variety of supercomputer architectures while preserving the functionality for the large NWChem user base. Now is the time for NWChem to be adapted to many-core.
De Jong and his team were given early access to the recently installed 9,688 Intel Xeon Phi nodes in the Cori Supercomputer. According to the Top500 list, Cori is one of the largest systems of its kind. After approximately a year of effort, the team wrote up their success in adding thread-level parallelism that can scale and exploit the many-core capabilities of the Cori Intel Xeon Phi processor-based supercomputer nodes. This paper resulted in the team being presented with their recent IXPUG best paper award. Succinctly, smart data distribution and communication algorithms were used enable DFT (Density Functional Theory) and hybrid-DFT methods to scale to large numbers of processors.
To assist in the many-core effort, Jacquelin utilized the roofline model to determine how much performance “headroom” was available to speed different kernels in NWChem. He found that existing libraries did not exploit all the performance capabilities of the many-core hardware, in particular for tall-skinny matrices, so the team developed a new approach. Jacquelin believes their work can potentially be applied to a variety of other HPC problems, “Because there are other areas of chemistry that also rely on tall-skinny matrices”. (Authors Note: This appears to be the case as Intel has added Tall-and-Skinny as well as Short-and-Wide Optimizations in the Intel Math Kernel Library (Intel MKL) 2017 updates 3.)
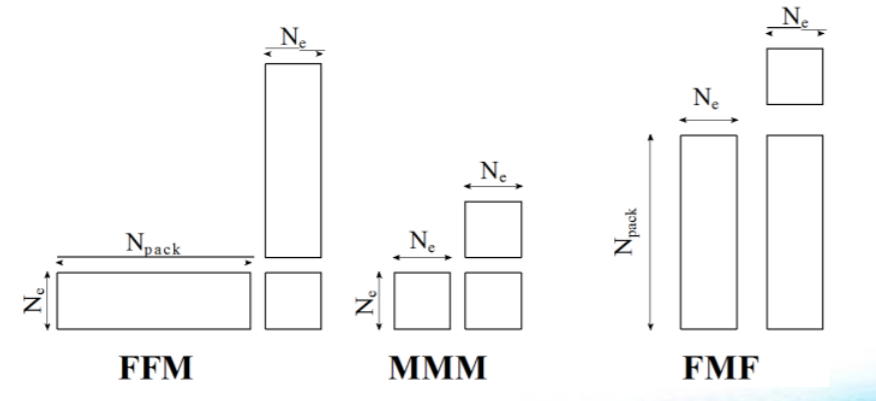
Figure 2: Sequence of matrix products of shape F or M (Source IXPUG)
The team also developed a pipelined approach for 3D FFTs. The Fast Fourier Transform is heavily used in a variety of 1D, 2D, and 3D HPC applications, so there could be other benefits of the NWChem many-core effort. The 3D Pipeline implementation is represented visually below.
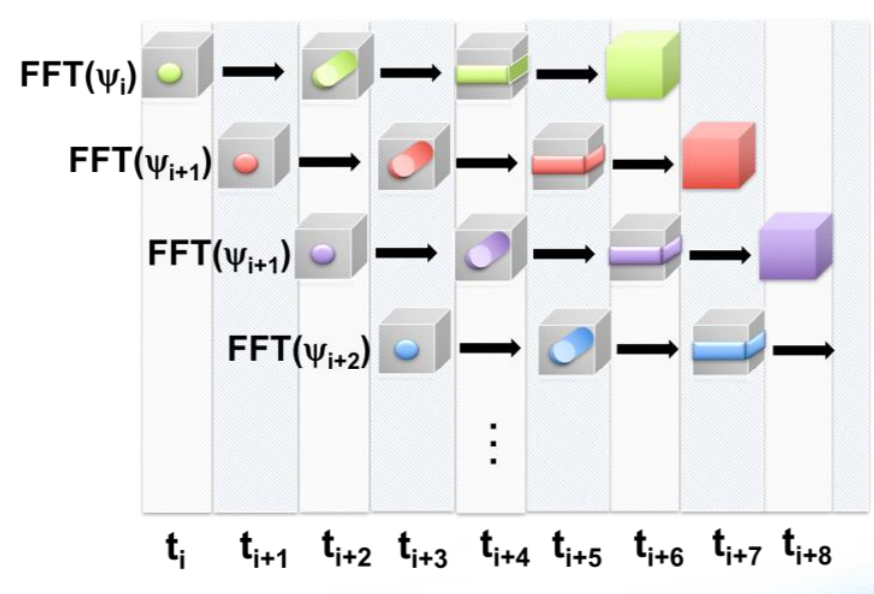
Pipelining of 3D FFTs to overlap communication and computation.
The team notes in their IXPUG presentation that they see strong scaling behavior on the many-core Intel Xeon Phi nodes to larger numbers of processing cores. This is due, they believe, to the on-package cache memory inside the Intel Xeon Phi processor plus the higher-bandwidth memory on the Cori processor boards.
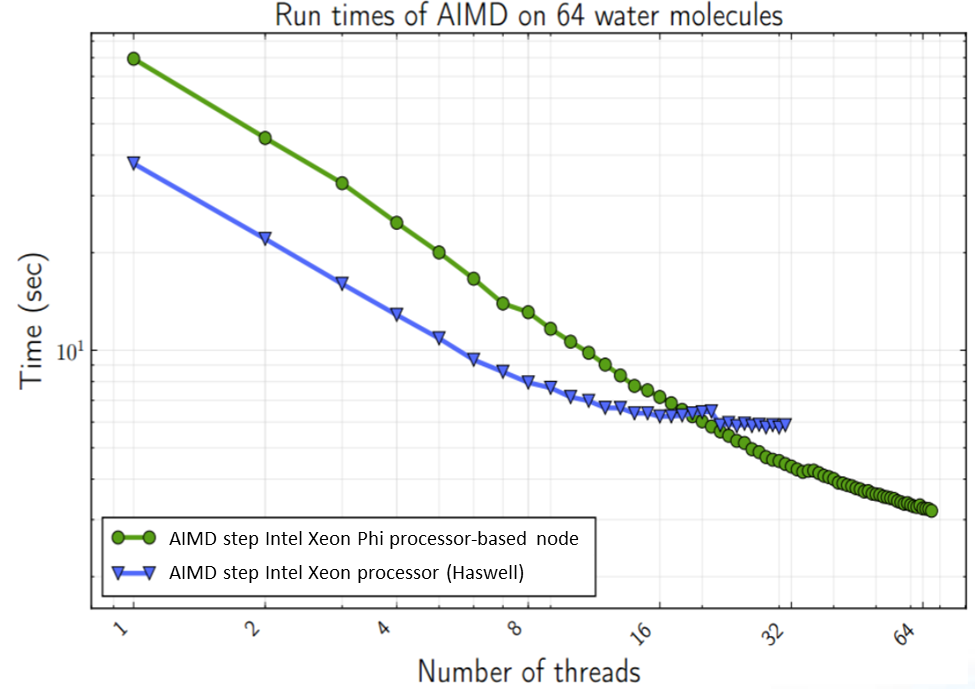
Intra-node strong scaling was tested by using a simulation containing 64 water molecules in a box. Fabric effects and cluster based strong scaling was tested using a 256 water molecules in a box benchmark. The Intel Xeon processor (Haswell) results were measured on a 32-core (hyperthreading disabled) Cray* XC40 2s Intel Xeon E5-2698v3 processor chipset. The Intel Xeon Phi processor results were also measured on a Cray XC40, except that the nodes were running Intel Xeon Phi 7250 68-core processors.
Overall, the team observes a 1.8x speed-up of Intel Xeon Phi processor over a Haswell generation Intel Xeon processor.
Scaling behavior without fabric effects (Source IXPUG – Note: Labels modified to reflect current Intel branding)
As is expected, interconnect latency becomes visible as the NWChem run is spread out over greater numbers of nodes. Even so, the Intel Xeon Phi nodes provide an important speed boost up to the point that the interconnect latency impacts performance.
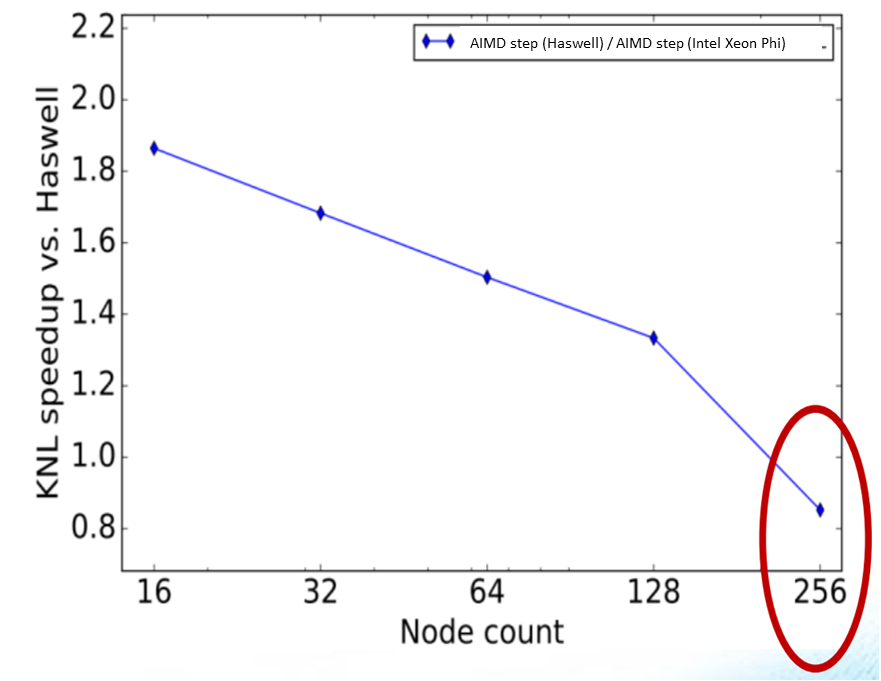
Impact of fabric latency on both Intel Xeon and Intel Xeon Phi nodes using the 256 water molecules in a box benchmark. (Source IXPUG)
Summary
Many-core scalability is currently a hot research topic that represents an important ingredient in building and running efficiently on an exascale supercomputer. Both accolades and best paper awards are being bestowed on projects that are setting records and bringing many-core capabilities to a global audience of users. In a very real sense, the focusing on many-core scalability presents opportunities to groups and individual scientists to make a big impact on the future of HPC as well as their own careers and group efforts.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. Rob can be reached at [email protected]
# # #
This article was produced as part of Intel’s HPC editorial program, with the goal of highlighting cutting-edge science, research and innovation driven by the HPC community through advanced technology. The publisher of the content has final editing rights and determines what articles are published.



