[Image courtesy of Adobe Stock]
By reducing dependence on human-labeled data, the algorithm enables AI systems to detect patterns in large, unstructured datasets. The approach has potential applications in everything from biology (e.g., genomic analysis and disease research) to finance (e.g., fraud detection and risk assessment).
One notable consideration with torque clustering is the question of explainability. Unlike supervised learning models that provide clear rationales based on labeled features, Torque Clustering’s logic—derived from complex gravitational dynamics—can be less transparent. As a result, it may be difficult to interpret why certain data points end up in the same cluster. However, this trade-off is often acceptable, even advantageous, when weighed against its autonomous discovery capabilities. By sacrificing some degree of human-interpretable rationale, the algorithm can reveal hidden structures in large, unlabeled datasets where traditional methods might falter or demand prohibitively expensive labeling.
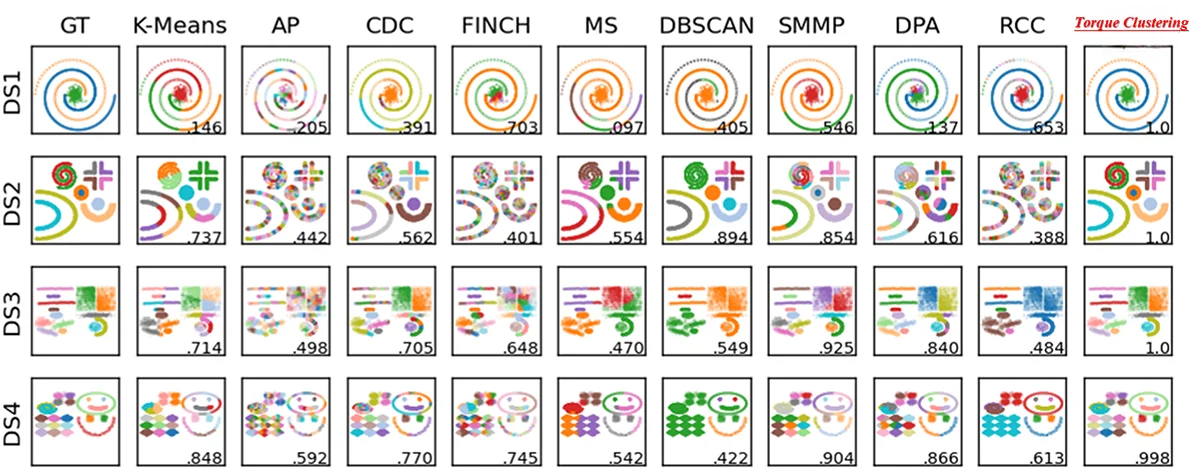
Autonomous clustering based on “fast find” of mass and distance peaks. [From the GitHub]
Gravitational principles
Torque Clustering is inspired by gravitational interactions, treating data points as though they have “mass” (based on local density) and “distance” (based on proximity). Smaller clusters merge with larger ones unless separated by significant gaps.
According to the development team, this physics-based approach can:
- Determine an optimal number of clusters without predefined inputs.
- Identify noise or outliers using global density thresholds.
- Adapt to varied data shapes, including non-convex clusters and high-dimensional spaces.
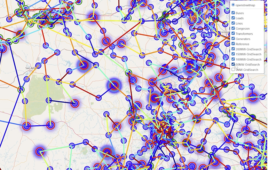
An independent exploration of torque clustering on Google Analytics data from R&D World’s website
What sets Torque Clustering apart is its foundation in the physical concept of torque, enabling it to identify clusters autonomously and adapt seamlessly to diverse data types, with varying shapes, densities, and noise degrees

Algorithmic overview
Torque clustering uses a four-stage process, which includes, first, assigning mass based on local density. Next up comes the application of torque calculations to guide cluster mergers according to mass-distance ratios. Third is the self-correction stage by reassigning points where needed. Finally, comes the refining of boundaries, filtering out noise while keeping clusters distinct.
The technique could have significant long-term potential. In the near term, the focus is on addressing computational costs: while the algorithm currently has “moderate” computational requirements, further optimization is needed for massive datasets. To enable broader adoption, open-source initiatives may prove crucial—a key strategy noted in a recent 1950.ai article. As with all AI, there is also a need to address bias and ensure ethical oversight.
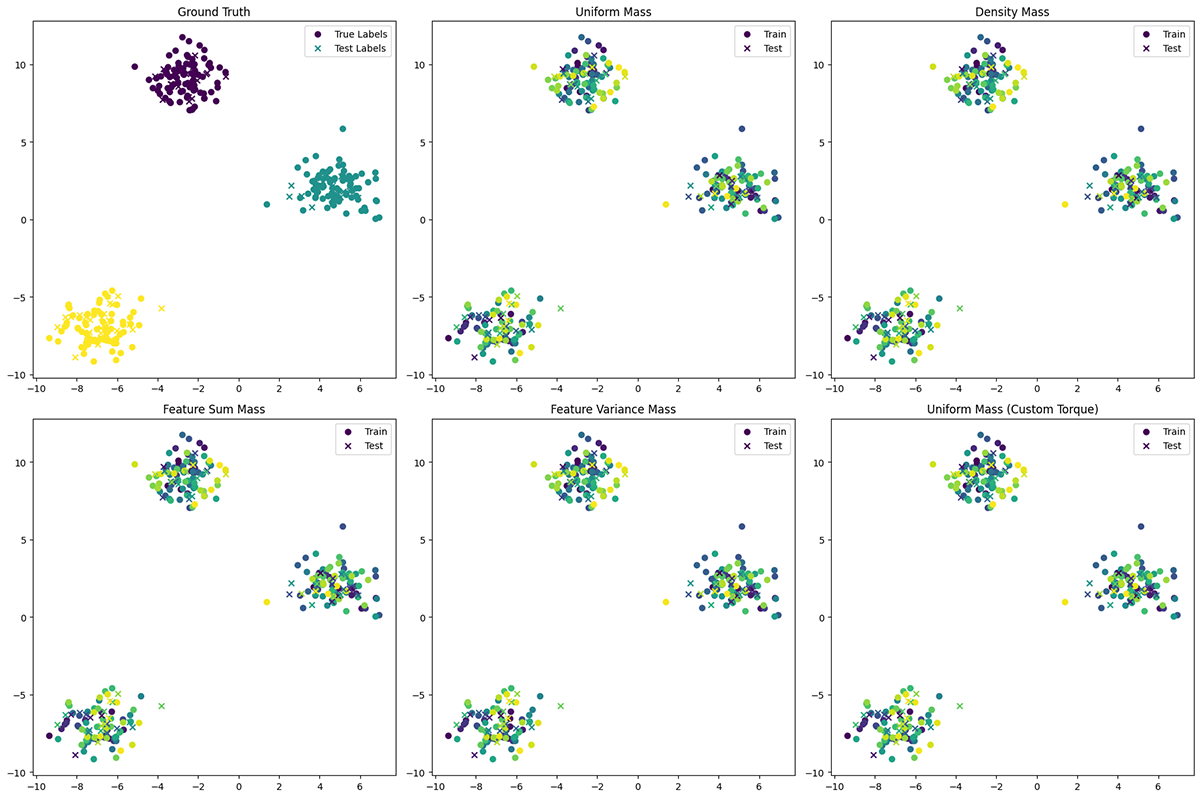
From a torque clustering demonstration shared on Colab
Beyond that, Torque Clustering aims to broaden the scope of unsupervised learning, which has historically focused on simpler clustering or basic dimensionality reduction. In contrast, this method moves toward a more advanced form of autonomous pattern discovery.
For more information, see the preprint: Jie Yang and Chin-Teng Lin, “Autonomous clustering by fast find of mass and distance peaks,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), DOI: 10.1109/TPAMI.2025.3535743