For too long, AI has been trapped in Flatland, the two-dimensional world imagined by English schoolmaster Edwin Abbott Abbott. While chatbots, image generators, and AI-driven video tools have dazzled us, they remain confined to the flat surfaces of our screens. Now, NVIDIA is tearing down the walls of Flatland, ushering in the era of “Physical AI” — a world where artificial intelligence can perceive, understand, and interact with the three-dimensional world around us.
How is this different from traditional robotics? Traditional robots are typically pre-programmed to perform specific, repetitive tasks in controlled environments. They excel at automation but lack the adaptability and understanding to handle unexpected situations or navigate complex, dynamic environments. Kimberly Powell, VP of Healthcare at NVIDIA, spoke to the potential in healthcare environments during her announcement at the JP Morgan Healthcare Conference:
Traditional LLMs, trained on vast text corpora, demonstrated remarkable linguistic capabilities but struggled with physical reasoning. Early attempts to integrate visual and spatial understanding through multimodal transformers showed promise but highlighted the need for fundamentally new architectures capable of processing real-world sensor data and understanding physical causality.
“Every sensor, every patient room, every hospital, will integrate physical AI,” she said. “It’s a new concept, but the simple way to think about physical AI is that it understands the physical world.”
Understanding is the crux of the matter. While traditional AI and autonomous systems could operate in a physical space, they have historically lacked a holistic sense of the world beyond what they need to carry out rote tasks.
Advanced AI systems are steadily making gains as the performance of GPUs accelerates. In an episode of the No Priors podcast featuring the NVIDIA CEO recorded in November, Huang revealed that NVIDIA had enhanced its Hopper architecture performance by a factor of five over twelve months while maintaining API compatibility across higher software layers. (It’s latest architecture is Blackwell) “A factor of five improvement in one year is impossible using traditional computing approaches,” Huang noted, explaining that accelerated computing combined with hardware-software co-design methodologies enabled NVIDIA to “invent all kinds of new things.”
Toward ‘artificial robotics intelligence’
In the same podcast, Huang discussed his perspective on artificial general intelligence, suggesting that not only is artificial general intelligence within reach, but artificial general robotics is approaching technological feasibility as well.
As Powell echoed a similar sentiment in her talk at JP Morgan. “The AI revolution is not only here, it’s massively accelerating,” she said. Powell noted that NVIDIA’s efforts now encompass everything from advanced robotics in manufacturing and healthcare, to simulation tools like Omniverse that generate photorealistic environments for training and testing.
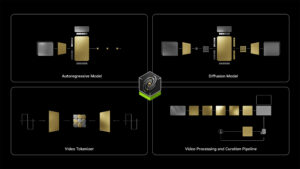
The image presents NVIDIA Cosmos’s four key architectural components: an Autoregressive Model for sequential frame prediction, a Diffusion Model for iterative video generation, a Video Tokenizer for efficient compression, and a Video Processing Pipeline for data curation. These components, unified by NVIDIA’s central design, form an integrated platform for physics-aware world modeling and video generation.
In a parallel development, NVIDIA has launched new computational frameworks for autonomous systems development. The Cosmos World Foundation Models (WFM) platform supports processing visual and physical data at scale, with frameworks designed for autonomous vehicle and robotics applications.
Tokenizing reality
At CES 2025 last week, Huang underscored just how different “Physical AI” will be compared to text-centric large language models: “What if, instead of the prompt being a question, it’s a request—go over there and pick up that box and bring it back? And instead of producing text, it produces action tokens? That is a very sensible thing for the future of robotics, and the technology is right around the corner.”
In the same No Priors podcast, Huang noted that the strong demand for multimodal large language models could drive advances in robotics. “If you can generate a video of me picking up a coffee cup, why can’t you prompt a robot to do the same?” he asked. Huang also highlighted “brownfield” opportunities in robotics—where no new infrastructure is required—citing self-driving cars and human-shaped robots as prime examples. “We built our world for cars and for humans. Those are the most natural forms of physical AI.”
The structural underpinnings of Cosmos

A promotional image for Cosmos [From the NVIDIA press release]
The vision for physical AI
The development of World Foundation Models (WFMs) represents a shift in how AI systems interact with the physical world. The complexity of physical modeling presents unique challenges that distinguish WFMs from conventional language models. As Huang explains, “[The world model] has to understand physical dynamics, things like gravity and friction and inertia. It has to understand geometric and spatial relationships.” This comprehensive understanding of physics principles drives the architecture of systems like Cosmos, which implements specialized neural networks for modeling physical interactions.
The development methodology for physical AI systems parallels that of large language models, but with distinct operational requirements. Huang draws this connection explicitly: “Imagine, whereas your large language model, you give it your context, your prompt on the left, and it generates tokens.”
The platform’s extensive training requirements align with Huang’s observation that “the scaling law says that the more data you have, the training data that you have, the larger model that you have, and the more compute that you apply to it, therefore the more effective, or the more capable your model will become.” This principle is exemplified in Cosmos’s training dataset of 9,000 trillion tokens, demonstrating the computational scale required for effective physical AI systems.

The image illustrates NVIDIA’s Isaac GR00T technology, showing a human operator using a VR headset to demonstrate movements that are mirrored by a humanoid robot in a simulated environment. The demonstration highlights teleoperator-based synthetic motion generation for training next-generation robotic systems.
Future implications
Physical AI has the potential to transform more than traditional users of robotics. In parallel with advances in physical AI, AI agents are also quickly expanding their skillsets. Huang describes such agents as “the new digital workforce working for and with us.” Whether it’s in manufacturing, healthcare, logistics, or everyday consumer technology, these intelligent agents can relieve humans of repetitive tasks, operate continuously, and adapt to rapidly changing conditions. In his words, “It is very, very clear AI agents is probably the next robotics industry, and likely to be a multi trillion dollar opportunity.”
As Huang put it, we are approaching a time when AI will “be with you” constantly, seamlessly integrated into our lives. He pointed to Meta’s smart glasses as an early example, envisioning a future where we can simply gesture or use our voice to interact with our AI companions and access information about the world around us. This shift towards intuitive, always-on AI assistants has profound implications for how we learn, work, and navigate our environment.
As Huang puts it, “Intelligence, of course, is the most valuable asset that we have, and it can be applied to solve a lot of very challenging problems.”
As we look to a future filled with continuous AI agents, immersive augmented reality, and trillion-dollar opportunities in robotics, the age of “Flatland AI” is poised to draw to a close, and the real world set to become AI’s greatest canvas.