While the mathematical capabilities of large language models such as ChatGPT are steadily improving, math is clearly not their forté. Not only is it extremely computationally efficient to ask such a model a math question, it isn’t all that hard to find word problems that trip up even the latest LLMs — like ‘how many R’s are there in the word strawberry?’ Evidently, there are two, according to some large language models.

But the situation is quickly changing. OpenAI is racing to launch a new AI model codenamed “Strawberry” that demonstrates enhanced reasoning capabilities, according to a report from the paywalled site The Information. This model, reportedly known as Q* before, aims to solve complex mathematical and programming problems it hasn’t encountered before, a feat that current chatbots struggle to achieve consistently. Beyond technical tasks, Strawberry is also reportedly capable of answering questions on subjective topics like marketing strategies and solving complex word puzzles. The model could become publicly available as soon as this fall.
OpenAI’s Strawberry and DeepMind’s AI Olympians

While there are no officially announced details, AI enthusiasts have speculated that a Sam Altman’s seemingly banal post on X about strawberries on August 7, 2024 is a tease for OpenAI’s forthcoming Strawberry model.
Strawberry is also helping create synthetic data for training an additional AI model known as Orion, thought to be a potential successor to GPT-4, which upon launch in March 2023 was a game-changing large language model. In the past 18 months, however, competition has largely caught up — and in some cases eclipsed OpenAI’s latest GPT-4–based models.
Other major players in the AI field are also making strides in mathematical reasoning. For instance, Google DeepMind recently has developed AlphaProof and AlphaGeometry 2, two AI systems for advanced mathematical reasoning. Working in tandem, the two systems had a silver-medal performance in the 2024 International Mathematical Olympiad, solving four out of six problems.
One of the central drivers of the performance boost of AlphaGeometry 2 over its predecessor, AlphaGeometry, is that it was trained on “an order of magnitude more synthetic data,” according to Google. “This helped the model tackle much more challenging geometry problems, including problems about movements of objects and equations of angles, ratio or distances,” it said.
Synthetic data as a driver of tangible model improvements?
Orion, the OpenAI model, is rumored to benefit from synthetic training data from a larger version of the Strawberry model. The Information article notes that the synthetic data could play a core role in reducing “hallucinations,” a significant limitation of current genAI systems that involves generating frequently plausible-sounding but incorrect data.
The project, rooted in earlier research by former OpenAI chief scientist Ilya Sutskever, has drawn comparisons to the ‘Self-Taught Reasoner’ (STaR) method developed at Stanford. StaR involves training language models to reason more effectively by generating explanations for their answers (rationales), filtering out incorrect ones, and then fine-tuning the model on these self-generated explanations. When news leaked about OpenAI’s Q* project in late 2023, some pundits framed the technology as a breakthrough toward Artificial General Intelligence (AGI), but little is known about it.
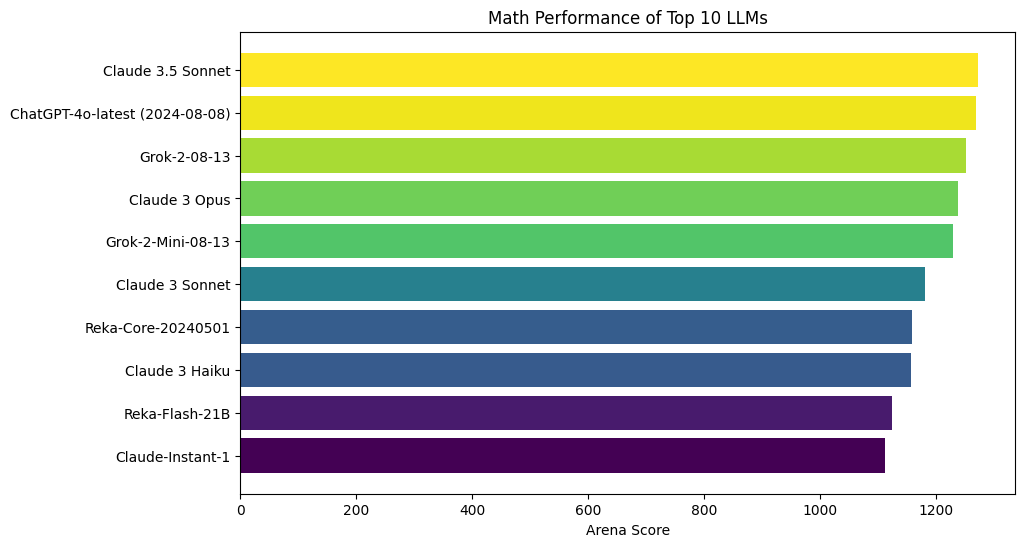
Math performance based on the Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference (Chiang et al., 2024).