Low-quality, poorly curated, and siloed scientific data costs advanced economies billions of dollars each year by draining researcher productivity, duplicating experiments, and slowing innovation.
Low-quality, poorly curated, and siloed scientific data costs advanced economies billions of dollars each year by draining researcher productivity, duplicating experiments, and slowing innovation.
A report commissioned by the European Commission estimated that failing to adopt FAIR (findable, accessible, interoperable, reusable) data principles costs Europe’s economy at least €10.2 billion annually owing to wasted researcher time and redundant work.
The problem is widespread. Gartner pegs the financial impact of poor data quality at nearly $13 million per organization. Similarly, the life sciences industry, as Pistoia Alliance’s 2024 “Lab of the Future” survey, flags inadequate data quality as the top barrier to implementing AI in R&D. More than half, 52% of respondents, pinpointed poorly curated datasets and another 38% citing non-FAIR data as barriers.
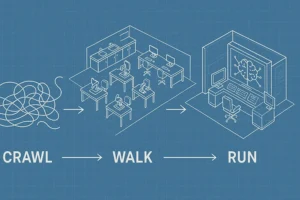
Crawl. Walk. Run. Integrate. Automate. Predict.
 Those lost hours — and the discoveries still locked in the data — set the stage for a June 11 webinar that brings together Michael Roberts, Ph.D., of the ISS National Lab, Parallel Bio technologist Ari Gesher, Labcorp digital-histology lead Paul Mésange, Ph.D. and Pfizer predictive-analytics chief Jonathan Crowther, Ph.D. The panel will lay out a practical “crawl-walk-run” blueprint for turning data chaos into a searchable, automated, analytics-ready lab environment, whether the lab is orbiting 250 miles above Earth or chasing tumor biomarkers on the ground.
Those lost hours — and the discoveries still locked in the data — set the stage for a June 11 webinar that brings together Michael Roberts, Ph.D., of the ISS National Lab, Parallel Bio technologist Ari Gesher, Labcorp digital-histology lead Paul Mésange, Ph.D. and Pfizer predictive-analytics chief Jonathan Crowther, Ph.D. The panel will lay out a practical “crawl-walk-run” blueprint for turning data chaos into a searchable, automated, analytics-ready lab environment, whether the lab is orbiting 250 miles above Earth or chasing tumor biomarkers on the ground.
To curb waste and surface hidden insights, labs need a deliberate, stepwise plan.
- Crawl means, for instance, corralling scattered files into a single source of truth, adding consistent metadata, and putting basic data-governance guardrails in place.
- Walk adds connective tissue. Think instrument hookups, template-driven data capture, dashboarding, and modest automation that removes manual copy-paste without upending how scientists work.
- Only when those rails are solid does the lab run: Here is where the fun begins. Machine learning, digital twins, and eventually, say, driverless workcells that spot anomalies, predict outcomes, and accelerate the pace of science.

A photo of the ISS National Laboratory [Image courtesy of ISS National Laboratory]
Hands-on lessons from bench to orbit
Each speaker in the webinar arrives with a hard-won experience. Labcorp’s Paul Mésange helped connect 20+ digital slide scanners across 14 sites into a global digital pathology network, and validated AI software that identifies and quantifies breast-cancer biomarkers, improving consistency and saving time. Parallel Bio’s Ari Gesher is building a “lights-out” automated lab where robots conduct immune-organoid experiments, and its AI-driven “Clinical Trial in a Dish” platform aims to accelerate preclinical drug discovery. Pfizer’s Jonathan Crowther spearheaded efforts to aggregate scattered clinical trial data. That work is enabling predictive models and real-time monitoring that help study teams proactively identify and mitigate enrollment risks. And ISS National Lab’s Michael Roberts oversees automated experiment modules in orbit, like self-contained labs and robotic experiment platforms, that stream microgravity data to Earth in real time. Together, they show how crawl-stage data plumbing can mature into advanced pipelines that accelerate scientific discovery.
Register for the free June 11 webinar here.