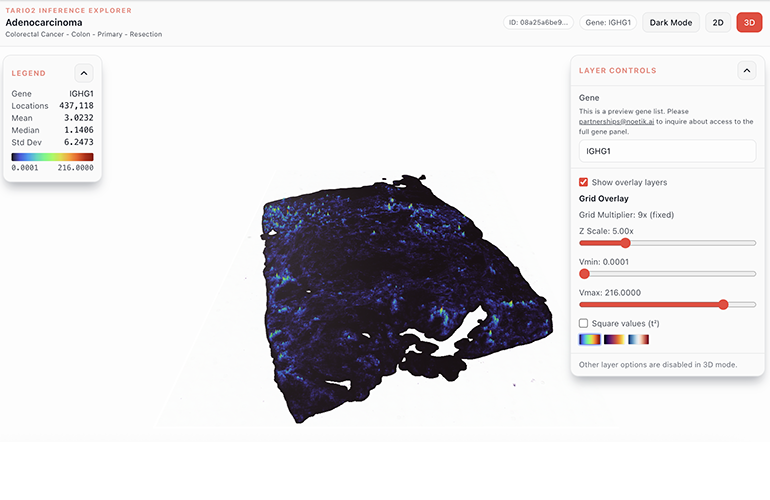
An image from the TARIO-2 Inference Explorer (Adenocarcinoma) | Noetik
Many patients who receive cancer immunotherapy do not respond to it, and oncologists still have few dependable ways to know in advance who will. By one estimate, only about 13% of all U.S. cancer patients stand to benefit from checkpoint inhibitors, and drugmakers are increasingly betting on AI to improve those odds.

Ron Alfa, MD, PhD
Noetik, a South San Francisco company that builds foundation models for cancer biology is among the firms following this arc. But it is approaching that problem from what CEO Ron Alfa, M.D., Ph.D., frames as a unique perspective on AI drug discovery. The company generates spatially resolved data from thousands of patient tumor samples to train models aimed at predicting which drugs will work in which patients. “If you’re following the AI drug discovery space, there’s a lot of activity around molecular-design foundation models that can make molecules,” Alfa said. “We’re tackling the other side of the problem: how do we build models that understand fundamental biology? What makes us different is that we generate a huge amount of biological data, and it all comes from patient samples.”
In work presented at ASCO 2026 and detailed in a white paper with its partner Agenus, a clinical-stage immuno-oncology company, Noetik reported that its model, TARIO-2, could identify which patients respond to Agenus’s hard-to-treat colorectal cancer immunotherapy using only the routine pathology slide collected for nearly every cancer patient at diagnosis. In a 49-patient retrospective response analysis, the top 30% of patients that the model ranked highest responded at 64%, against 9% among the rest. In a separate 47-patient survival analysis, the top-ranked group had not reached median overall survival, versus 13.3 months for the others, a hazard ratio of 0.18.
A world model for biology
Noetik calls TARIO-2 a “world model,” a term it borrows from the AI systems that learn to simulate an environment well enough to predict its next state. The idea grew out of reinforcement learning and has gained currency in AI over the past few years, championed most visibly by Yann LeCun, the Turing Award winner who left Meta in late 2025 to build a startup around the approach. The technique is most visible in robotics, self-driving, and video generation, and has been rare in biology. “The reason we call it a world model is that it’s trained on … thousands of patients with spatial context, so it actually has the ability to simulate biology,” said Lacey Padrón, Ph.D., Noetik’s chief technology officer. The model can be asked counterfactual questions, she said, like “What if there were a T cell here?” or “What if this gene turned off?”

Lacey Padrón, PhD
That ability to simulate points at a stubborn clinical question: which patients a given therapy will actually help. It remains a core challenge across oncology, and it is hardest in immunotherapy.
Even the field’s most advanced checkpoint drugs work in only a minority of patients with these refractory cancers, roughly one in five in the trials behind the paper, and standard biomarkers such as PD-L1 and tumor mutational burden predict response poorly. Much of the missing signal sits in the spatial arrangement of the tumor and the immune cells around it, which is expensive and tissue-hungry to measure directly.
That is where the H&E slide comes in. Hematoxylin and eosin staining is the century-old default in pathology, performed on essentially every cancer biopsy and then read by eye. TARIO-2 needs nothing more than that image. From it, the model reconstructs a spatial picture of the tumor microenvironment, including an inferred readout of gene activity across nearly 19,000 genes at single-cell resolution, the kind of molecular detail that normally requires specialized and costly spatial assays. That edge shows up head to head: scoring response from a single H&E slide, TARIO-2 reached an AUROC of 0.81, against 0.68 for GigaPath and 0.44 for H-Optimus-0, two leading H&E-only foundation models trained on far larger slide collections.
The result, and the trial behind it
Noetik ran TARIO-2 on the Agenus study of botensilimab plus balstilimab (BOT+BAL), scoring each patient from a single pretreatment H&E slide and then checking those scores against who actually responded. The model played no part in running the trial, and its foundation model was pretrained without these samples. For the retrospective analysis, Noetik used TARIO-2’s inferred features to train separate response and survival models against the trial’s outcomes, then evaluated them with out-of-fold cross-validation. “This is not even our data, we’re getting it from another company, we have nothing to do with running the trial,” Alfa said, “and you can see that, yes, they can predict which patients are responding.” He is careful about what that proves: “We need to run a clinical trial ourselves to show this prospectively, but it’s the closest thing you could possibly get to proving the models are working.”
The headline figures come from the study’s largest cohort: 49 patients with microsatellite-stable metastatic colorectal cancer and no active liver metastases, a subset of the 113 efficacy-evaluable patients treated with the combination.
BOT is an Fc-enhanced anti-CTLA-4 antibody designed to boost anticancer immunity through two routes: activating immune cells that attack tumors and depleting the regulatory immune cells that restrain those responses. BAL is an anti-PD-1 antibody, pharmacologically similar to approved PD-1 inhibitors, intended to sustain the immune response against cancer. Agenus brought the problem to Noetik, Padrón said: the drugs were “working in about 20% of patients in their trials, but they haven’t identified any biomarkers that can tell them who those patients are.” That was the basis of the collaboration.
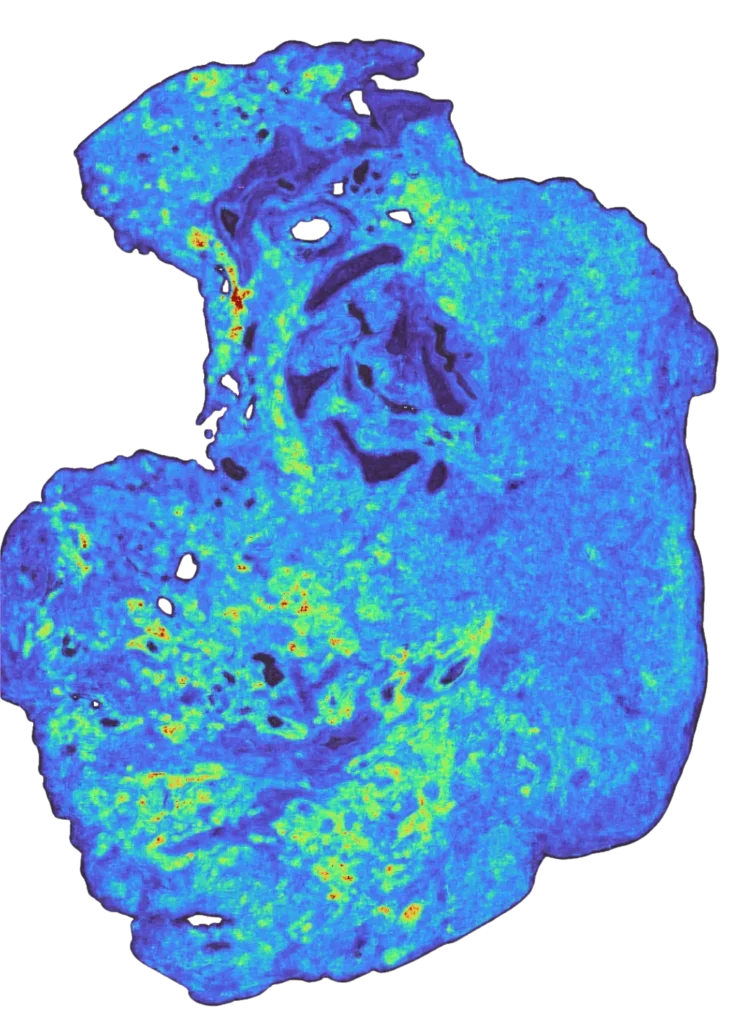
A TARIO-2 prediction of spatial gene expression across a tumor section, inferred from a routine H&E slide alone. Warmer areas (yellow to red) mark higher predicted expression, cooler areas (blue to purple) lower. | Noetik
The data engine behind TARIO-2
Closing that biomarker gap is a data problem before it is a modeling one. A model can only learn to read the tumor microenvironment from a routine slide if it has first seen that microenvironment measured directly, in enough patients to generalize, and no such training set exists off the shelf. So Noetik built its own. The company sources formalin-fixed tumor samples across 19 cancer indications, cuts 12 to 24 computationally selected cores from each into tissue microarrays, and profiles adjacent sections with three aligned modalities: H&E, 16-plex immunofluorescence and whole-transcriptome spatial transcriptomics on the CosMx platform. The dataset now spans more than 5,000 patients, including over 725 colorectal, 605 sarcoma and 474 ovarian cases.
Sourcing was the easy part, at least at first. The bigger challenge, Padrón said, is “finding ones that were fit for purpose: high quality, handled properly in the lab beforehand, and large enough that we could actually do this coring.” The company’s appetite for samples is beginning to outrun the supply, she said, leaving it “having to think more creatively.”
The scale of what Noetik has amassed so far is part of its moat, and, Alfa argues, a single profile carries far more signal than a genome does, which is what makes it expensive to produce and hard to copy. “With a genome sequence, you average all of it to get one read per gene, one piece of signal per gene,” Alfa said. “For this spatial data … I have 19,000 images, each image represents a gene, and there are hundreds of cells in all these images. You have this rich network of interconnected data that you’re training on. It’s a lot more powerful, and it also takes a lot more time to generate at scale.” The set that goes into training, Padrón said, “ends up looking more like 100 terabytes,” and is still growing “at a rate of a couple percent every week.”
The backstory on the GSK partnership
In January, Noetik inked a five-year licensing deal with GSK that it framed as a new paradigm for the industry, giving GSK a nonexclusive license to its OCTO-VC foundation models in non-small cell lung cancer and colorectal cancer. The agreement includes $50 million in upfront capital and near-term milestones, plus annual licensing fees. Alfa said: “People ask us all the time: ‘We did a $50 million deal with GSK. Why did they want to do that with you? Why don’t they just generate all this data?'”
Alfa notes that the build versus buy decision for GSK was straightforward. “We’ve shown that we can source the samples, generate the data, and train the models, that full stack of capabilities,” he said. “The other thing about this data is that it doesn’t exist out in the world, so even if you’re an AI researcher who wants to train models similar to ours, you just don’t have the data to do it.”
Studies pairing H&E with spatial transcriptomics typically run 20 to 40 patients, Alfa said; Noetik has profiled more than 5,000. “It’s not one order of magnitude, it’s at least two orders of magnitude already,” he said, “and there will be three soon.”
The physical tissue compounds that lead. Every incoming sample yields 10 archived slides, Alfa said, gesturing toward cabinets of unprocessed material. “What’s really unique is that it’s a data asset, but it’s also a biobank/specimen asset, so we can always go back to any one of these patients over time and generate more data.” A new assay, or a stain a partner asks for later, can be run on the same banked patients. The generating operation is scaling to match: a two-week run processes two tissue arrays, about 80 patients. “Apart from the manufacturer, I think we have the largest operation generating this type of data,” Alfa said, “and we still want to scale more.”




Tell Us What You Think!
You must be logged in to post a comment.