Dario Amodei (left) and Mike Krieger at Anthropic’s healthcare event during JPM Week.
Anthropic used JPMorgan’s annual healthcare conference to make its biggest push yet into medicine. The announcement included HIPAA-ready enterprise deployments, connectors to standard medical databases like ICD-10 and the CMS coverage registry, and new AI “skills” for tasks like prior authorization and clinical trial protocol drafting.
At the event, CEO Dario Amodei shared a story about his sister, Anthropic co-founder Daniela Amodei, to illustrate AI’s potential in healthcare.
“While she was pregnant, she had an infection,” Amodei said. “She went to a bunch of fancy doctors, and for some reason, they all thought that this was a viral infection. And she just uploaded her data to Claude, and Claude basically gave a second opinion where Claude said, ‘I think this is a bacterial infection.’”
The Ceiling and the Floor
The ceiling: The superhuman AI promise (and the evidence gap)
For years, a handful of investors and pundits have predicted AI would have a decidedly disruptive impact in healthcare In 2012, venture capitalist Vinod Khosla argued that machines would eventually replace 80% of what doctors do, while in 2016, AI pioneer Geoffrey Hinton famously declared we should ‘stop training radiologists’ because algorithms would soon surpass human capability.
While such radical predictions remain outside the mainstream, large language models have lent them credence by acing medical licensing exams. Emerging evidence, however, suggests that when tested against real-world complexity, these models still fall decidedly short of expert capability. In a script concordance benchmark measuring how clinicians update beliefs as new information arrives, OpenAI’s o3 scored 67.8%, while o1-preview scored 58.2% and DeepSeek R1 hit 55.5%. (Newer models tend to fare better.) The authors also found response patterns consistent with overconfidence, leaning too hard on extreme belief shifts and rarely choosing “no change,” as CoLab noted.
On a separate open diagnostic reasoning benchmark (DiagnosisArena), reported accuracy was 45.82% for o3-mini and 31.09% for o1, according to an arXiv preprint.
The floor: A system under strain
Even if the current commercial AI models are not a replacement for traditional physicians, their ability to synthesize medical knowledge quickly could prove valuable considering that many physicians work grueling hours and have limited time to focus on a single patient. Recent surveys still put physician burnout in the “roughly four in ten” range: 43.2% reporting at least one symptom in 2024. (AMA) A 2022 University of Chicago study found that for a primary care doctor to follow all national care guidelines, they would need to work 26.7 hours per day.
Strain correlates with safety risk. In a large U.S. survey summarized by Stanford Medicine, 10% of physicians reported a major medical error in the prior three months, and those with burnout had more than twice the odds of reporting such an error. as Stanford Medicine noted.
Time pressure is pervasive: one multi-site study found 67% of clinicians said they needed more time than allotted for new-patient visits and 53% for follow-ups, as an article in Springer found.
Against that floor, an AI that reliably surfaces guideline checks, flags contraindications, and asks sensible follow-up questions could function as a safety net.
Amodei recounted that the chatbot identified a risk of the infection turning systemic and discussed the possibility of taking antibiotics “in the next 48 hours, or you might actually be at serious risk.” After relevant testing, the model was proven right.
“Were the doctors smart enough to figure this out? Of course. But they were busy, and they were dealing with a bunch of patients,” he said. “The model seems superior in its ability to be consistent, in its ability to be patient, in its ability to not be overloaded.”
Yet, the anecdote is a sample of one. While that represents a success story, Amodei stopped short of saying that Claude should be a replacement for a doctor. “It’s what I just said; it’s a second opinion, and that is usually very helpful,” he said. “And the model may go in directions that a human is unlikely to go in.”
Some doctors have been probing the role of off-the-shelf, as well as custom AI models, in providing a second opinion. A study published in the Journal of General Internal Medicine involving older LLM models, including Claude 3.7 Sonnet, offered contradictory advice up to 40% of the time across repeated sessions.
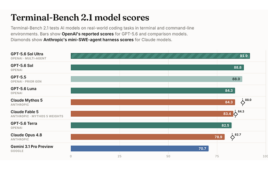
Recent models have made steady gains in terms of medical textbook–type knowledge, scoring above 95% in answering MedQA questions, a multiple-choice OpenQA dataset for solving medical problems. Specifically, Anthropic touted the performance of Claude 4.5 Opus on task-oriented tests: MedAgentBench (workflows like scheduling and lab orders) and MedCalc Bench (medical calculations), where Opus 4.5 scored 92.3% and 61.3% respectively, marking significant improvements over earlier models.
But those benchmarks measure well-defined tasks with verifiable answers, not the kind of judgment-dependent decisions where variance becomes a problem. Anthropic’s own life sciences lead, Eric Kauderer-Abrams, Head of Life Sciences, Anthropic, tempered expectations during the demo: “Our guidance is not to just let Claude run open-loop and write clinical trials and communicate directly with FDA and cut you out of the loop. That’s not where the technology is today.”
Instead, think of Claude output as a working draft. “We’re saying that you should use Claude to make that draft of a clinical trial protocol, right?” Kauderer-Abrams said. “And in doing so, you’re amplifying what your clinical affairs teams can do and saving weeks of time. And that’s all available right now today.”
Amodei noted that because his sister was using the consumer Claude app, she had to manually compile and upload her data: a task the average patient might not figure out, leading to disparities in care. He suggested that doctors could eventually use Claude to help decide which tests to order, but that structural barriers currently stand in the way.
“I think there’s a huge overhang where a lot is possible, but it’s being blocked by security, legal, various kinds of software plumbing,” Amodei concluded. “And that’s the thing we need to work on together.”