Anthropic art from the Sonnet 4.5 launch
Anthropic boasts that its latest model, Claude Sonnet 4.5 is “the best coding model in the world.” It says: “It’s the strongest model for building complex agents. It’s the best model at using computers. And it shows substantial gains in reasoning and math.”
The debut also lands amid a noisy few weeks of user gripes about regressions and limits of prior models, setting up 4.5 as both a technical upgrade and a reputational reset.
So far, feedback online for the model, as it was for OpenAI’s GPT-5, is mixed.
Early adopters of Sonnet 4.5 cite quirky but improved coding capabilities while others claim that the model is overly assumptive. Multiple subscribers to the company’s Pro and Max tiers, say they’re capping out faster than before, with some alleging silent reductions and questioning value at higher tiers.
In terms of claimed benchmarks, Sonnet 4.5 leads Anthropic’s own chart on SWE-bench Verified (n=500), posting 77.2% accuracy in standard runs and 82.0% with parallel test-time compute (the asterisked figure). That edges its prior state-of-the-art model Opus 4.1 (74.5% / 79.4%), Sonnet 4 (72.7% / 80.2%), and tops the single-run scores shown for OpenAI’s specialized coding model GPT-5 Codex (74.5%), GPT-5 (72.8%) and Google’s Gemini 2.5 Pro (67.2%).
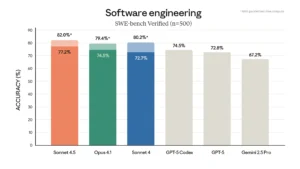
To understand what these numbers mean: SWE-bench Verified is a real-world software engineering benchmark built from GitHub issues in popular Python repositories, where each task presents the model with a failing test or issue along with the full codebase, and the model must propose a patch that actually fixes the bug. A task only counts as correct if the patch applies cleanly and all the repository’s tests pass in a clean environment. There’s no partial credit. The “n=500” designation means this run used a 500-problem, human-curated subset with reliable setup and ground-truth fixes, and the accuracy percentages represent the solve rate: how many of those 500 issues the model successfully fixed end-to-end.
The asterisked scores come with a caveat. Anthropic’s methodology for the aforementioned 82% figure with parallel test-time compute involves sampling multiple parallel attempts, discarding any patches that break visible regression tests, then using an internal scoring model to select the best candidate from the remaining attempts, essentially giving the model multiple tries and picking the best one. The 77.2% single-run score is the more conservative baseline, though Anthropic notes it used a minor prompt addition instructing the model to “use tools as much as possible, ideally more than 100 times” and to “implement your own tests first before attempting the problem.” As of September 30, Claude Sonnet 4.5 has not yet appeared on key third-party leaderboards like LiveCodeBench (which updates monthly with fresh problems to reduce training contamination) or LMSYS Chatbot Arena’s crowd-sourced rankings.
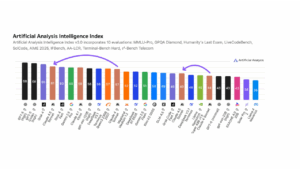
A cross-vendor scorecard. Independent tester Artificial Analysis ranks Sonnet 4.5 (Thinking) #4 on its Artificial Analysis Intelligence Index, a composite of 10 public evals: MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME 2025, IFBench, AA-LCR, TerminalBench-Hard and τ²-Bench Telecom. Sonnet 4.5 scores 61, up from 59 for Claude 4.1 Opus (Thinking) and 57 for Claude 4 Sonnet (Thinking). On the same scale, GPT-5 (high) leads at 68, with Grok 4 at 65 and Gemini 2.5 Pro and Grok 4 Fast at 60. In non-reasoning mode, Sonnet 4.5 rises to 49 (from 44). The index also notes token-efficiency gains for Sonnet 4.5 in reasoning mode.
Claude Sonnet 4.5 in context: Artificial Analysis Intelligence Index rankings
| Model | Score (Thinking Mode) | Score (Standard) |
|---|---|---|
| GPT-5 (high) | 68 | – |
| Grok 4 | 65 | – |
| Gemini 2.5 Pro | 60 | – |
| Claude Sonnet 4.5 | 61 | 49 |
| Claude Opus 4.1 | 59 | – |
| Claude Sonnet 4 | 57 | 44 |
Composite score across 10 public benchmarks: MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME 2025, IFBench, AA-LCR, TerminalBench-Hard, τ²-Bench Telecom