Upon launch, Anthropic hailed Claude Sonnet 4.5 as the best coding model in the world. The model launched on September 29 with a lead on real-repo coding (SWE-bench Verified) and a big jump in “computer use” (OSWorld). Anthropic reports 77.2% on SWE-bench Verified and 61.4% on OSWorld; in press briefings they also cited 82% on SWE-bench with parallel test-time compute.
One week in, early benchmark data and hands-on testing are starting to paint a more nuanced picture. For R&D teams using agentic coding tools, the takeaway is clear: code reliability and desktop automation show real gains, while physical reasoning lag.
In the LMArena leaderboard (last updated on October 3), the model shows divergent performance across domains. In the Text arena, the model sits in a multi-way tie at the top with a score of 1453, alongside Gemini 2.5 Pro (1452) and Claude Opus 4.1 (1449). Yet in the WebDev arena, where models are evaluated on coding and web development tasks, Claude Sonnet 4.5 ranks 4th with a score of 1382, trailing GPT-5 (high) at 1478, Claude Opus 4.1 variants, Gemini 2.5 Pro (1403), and DeepSeek-R1 (1394).
Better than its predecessor and fast
Third-party evaluator Artificial Analysis has integrated Claude Sonnet 4.5 into its composite Intelligence Index, where the model scores 63 out of 100, ranking seventh overall among current frontier models. That places it up from 61 for Claude Opus 4.1 and 57 for Claude Sonnet 4, but trailing GPT-5 Codex (high) and GPT-5 (high) at 68, GPT-5 (medium) at 66, o3 at 65, and Grok 4 at 65. The index aggregates results from 10 public benchmarks including MMLU-Pro, GPQA Diamond, LiveCodeBench, and AIME 2025.
A comprehensive benchmark analysis from All-in-One AI shows Sonnet 4.5 represents a 25.7% intelligence gain over Claude 3.7 Sonnet, with improvements in coding performance and computer use. The analysis includes an interactive speed simulator comparing token generation rates across models.
Coding and computer-use gains map neatly to lab and engineering workflows: parsing instrument logs, wrangling spreadsheets, building small internal tools, triaging bugs, and glueing apps together. But on a simple physics-intuition check (the Visual Physics Comprehension Test), community runs using that dataset put Sonnet 4.5 only modestly above chance. In other words, it can ship code and click buttons, but you shouldn’t trust it yet to reason about real-world dynamics without strong guardrails.
What the new benchmarks say
Coding (SWE-bench Verified). Anthropic’s post shows Sonnet 4.5 leading standard runs at 77.2%. Outlets also reported 82.0% when evaluators use parallel test-time compute (beam/batch selection), a setup many production teams emulate to raise pass rates. Third-party analysis shows this represents the best coding score among widely tested models on this real-repo benchmark.
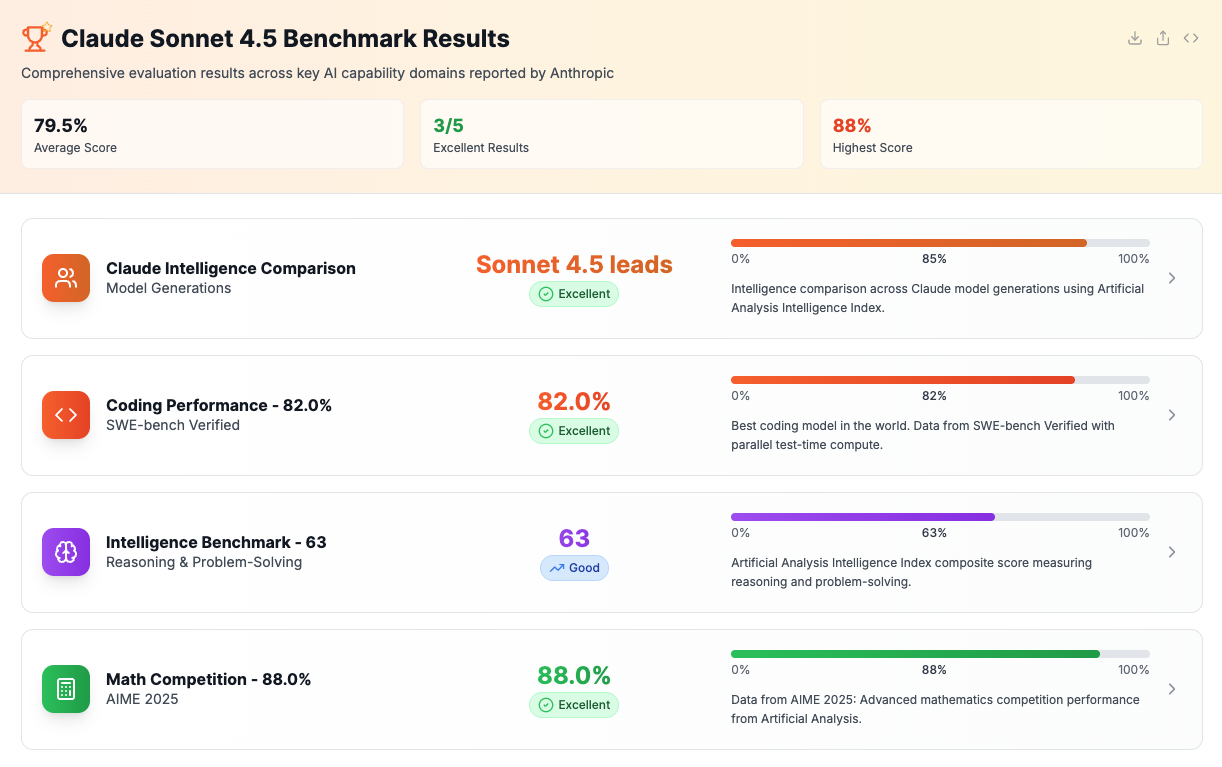
Chart source: https://all-in-one-ai.co
Computer use (OSWorld). Sonnet 4.5 posts 61.4% on OSWorld vs. 42.2% for Claude 4 earlier this summer, a 45% improvement that’s directly relevant to repetitive data entry, dashboard hygiene and multi-tool lab admin tasks. This represents one of the model’s clearest wins over competitors.
Math and “intelligence” composites. Third-party aggregators show Sonnet 4.5 improving over Anthropic’s prior flagships on reasoning composites and AIME-style math (88% accuracy, up from 80.3% for Opus 4.1) — but scores vary by configuration (tools on/off, sampling, context). The All-in-One AI benchmark report tracks these variations and provides normalized comparisons across the Claude model family. Use these as directional deltas, not absolutes.
Physics intuition. Community runs on the VPCT (ball-and-bucket toy problems) suggest Sonnet 4.5 hovers around 39.8%—not far above random guessing (33.3%) and far below humans (100%). That’s your robotics/automation caveat: great at the software layer; still brittle at grounded physical prediction.
Speed and latency. At 63 tokens per second median output speed and just 1.80 seconds to first response (E2E latency), Claude Sonnet 4.5 ranks among the fastest-responding frontier models—a practical advantage for interactive development workflows. An interactive speed comparison tool lets developers simulate real-time generation against other models.
Safety and “situational awareness.” Anthropic’s system card and media coverage note the model sometimes recognizes it’s under evaluation (~13% of automated tests) and may refuse odd setups. That’s arguably good for safety but complicates reading some evals; R&D deployments should log configs and report both “standard” and “beam/parallel” results.
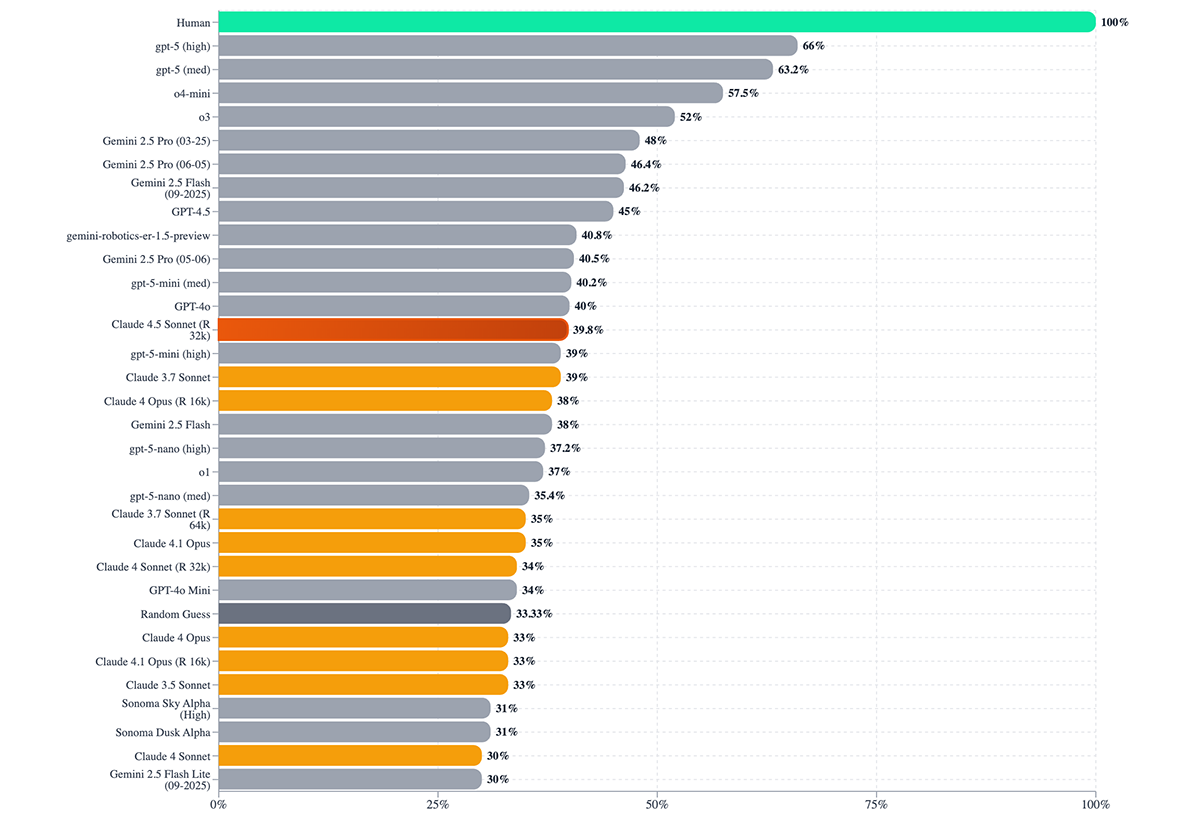
Chart source: https://all-in-one-ai.co
Pricing and access
API pricing remains Sonnet-tier: $3 per million input tokens and $15 per million output tokens—unchanged from Claude Sonnet 4, making the improvements essentially “free” from a per-token cost perspective. Availability includes Anthropic’s API, Amazon Bedrock and Google Vertex AI. For large batch jobs (agents, test-time search), budget for parallelism.
However, user reports suggest rate limits on Pro ($20/month) and Max ($200/month) subscription tiers may be tighter with 4.5 than with prior models, leading some power users to characterize the model as “technically impressive but financially inaccessible” despite nominal pricing remaining flat.
For a complete breakdown of Claude Sonnet 4.5’s performance across domains, including interactive comparisons and detailed benchmark methodology, see the full benchmark report from All-in-One AI.