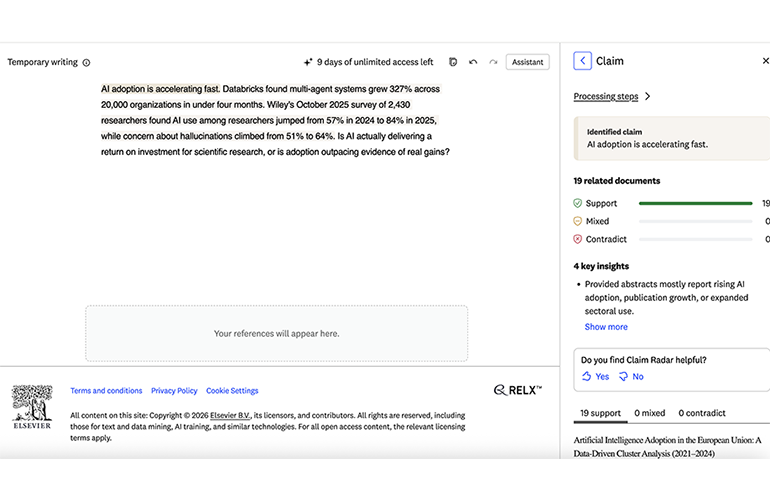
LeapSpace’s Claim Radar analyzing the claim “AI adoption is accelerating fast,” pulling 19 supporting references and zero contradicting ones.
2025 was supposed to be the year of the AI agent. But 2026 arguably deserves that title. Adoption is climbing fast. One vendor tracking agent-building across 20,000 organizations found multi-agent systems grew 327% in under four months. Everyone from startups to big tech is shipping agents and agentic frameworks, including for science. Elsevier’s LeapSpace, which went live in January and added an agentic layer on June 25, is the latest example. That layer brings writing support, claim verification and evidence comparison, grounded in more than 20 million full-text peer-reviewed articles and books, plus roughly 100 million Scopus records (the abstracts-and-citations layer of Elsevier’s publisher-neutral database, metadata rather than full text, spanning 7,000+ publishers).
Elsevier says the latest LeapSpace tools are built for end-to-end research workflows. Elsevier’s own survey puts the payoff at 97% of users reporting time savings, more than half of them saving over half their research time (Elsevier, N=556). “In the last year we now have thousands of organizations and several hundred thousand monthly users across academic and many corporate R&D-intensive clients,” said Cameron Ross, Elsevier’s SVP of generative AI for corporate markets, describing the lineage LeapSpace builds upon, including ScienceDirect AI and Scopus AI. “The things we’ve released are a direct response to the feedback and engagement of all our users.”

Cameron Ross
Inside writing coach
One of the chief new features is Writing Coach, a private drafting space where a researcher can write, or drop in text they have already written, and have the system pressure-test the argument against the literature.
“What we’re really trying to work through is that the world is full of wild assertions,” Ross said. Scholarly writing rarely traffics in the wild kind, though it is thick with contested ones. “There may be dissonant views,” he said. The tool helps a researcher gauge how well an argument aligns with consensus and what kind of evidence there is to support it.
Mechanically, Writing Coach segments a draft into its individual claims and runs each through the peer-reviewed corpus. It tags each one supported, mixed, or contradicted and tallies the references on each side. What draws Ross’s attention is not the pile of agreement but the friction. “Every time I use this tool I want to zoom into the outliers. What are the contradictors?” he said, adding that the instinct showed up across Elsevier’s user studies: “A lot of our clients are asking: how could you visualize or show the outliers, what’s contradictory, or what’s supporting this research?”
In a live demo, Ross fed in a draft on the return on investment of AI; the tool isolated a claim about AI adoption and pulled back roughly two dozen references, which he could sort into the ones backing it and the ones pushing against it.
The draft Ross chose to demo was about AI itself, examining the themes of whether the technology delivers a return on investment, and the scope of potential occupational disruption from the technology. Such questions are top of mind for many professionals, including scientists and researchers. “Is everything going to be automated in five years? I know that’s a concern for many people,” he said.
Balancing recency vs. consensus
In the demo, Ross noted how LeapSpace mined through literature. “It segments and breaks up my text into a number of the claims I’m making or exploring,” he said. “If you click here, it passes through the literature and looks for substantiating or contradictory evidence.”
The analysis is based on peer-reviewed scholarly literature: journals, books, conferences. When asked how emerging data points and shifts in expert opinion influence the Writing Coach and Claim Radar, Ross said LeapSpace is designed to focus more on a historical perspective. A discrete new figure, for instance, will not appear until it reaches the literature. Or if there is a piece of news relevant to the query, “it would not be here,” Ross said. Still, he noted the scientific content underneath refreshes constantly. “The underlying content sets, from a scientific perspective, are updated daily within our product. But it will not be as current as a news site.”
But on the flip side, the system allows users to add context. “I would argue: put it within the Writing Coach and build it in,” Ross said.
Scientific consensus, of course, is also constantly maturing. And sometimes prior research anticipates the present with striking precision. As Ross spoke, a record heat wave was baking Europe, with temperatures approaching 40°C in London, and he used it to make his point. “What we think is late-breaking news was entirely predicted and well grounded for decades,” he said, describing a search that pulled up climate papers projecting exactly the pattern of intensifying European heat waves now playing out. One such paper, Fischer and Schär’s 2010 study in Nature Geoscience, projected that heatwave days across the Iberian peninsula and Mediterranean would climb from about two per summer in 1961–1990 to roughly 13 by 2021–2050, with the number of distinct heatwaves rising toward two to three per season later in the century. The same logic, he said, applies to markets: an AI build-out that dominates today’s headlines can be read against decades of literature on earlier technology and investment cycles.
Elsevier’s play to win trust in AI
Researchers are adopting AI faster than they are learning to trust it. Elsevier research indicates that only 22% of researchers view AI tools as trustworthy. Meanwhile, Wiley’s October 2025 ExplanAItions survey of 2,430 researchers found the share using AI in their work jumped from 57% in 2024 to 84% in 2025. Meanwhile, concern about inaccuracies and hallucinations climbed from 51% to 64%, and the share who believed AI already outperformed humans on most tasks fell from more than half to under a third. “We all know what the foundation of an LLM is,” Ross said. “It’s a probabilistic engine designed to give you a word or sentence that’s grammatically correct. Is it factually correct? Be careful.” Ross added that scientists “can’t afford to be catastrophically wrong.”
Many scientists, especially in highly regulated fields like pharmaceuticals, aerospace and defense, have significant requirements for privacy. Research-grade decision-making “needs super-private and secure tools,” Ross said, “but it’s also grounded in peer-reviewed fact.” Elsevier says customer data stays private and is never used to train third-party models, and that Word documents uploaded into the workspace remain encrypted and walled off from any model training. “We do not train, and we do not tune models,” he said. The customer’s own material stays outside that loop too, he said: “Neither on the content nor on the input of the customer.”

Tell Us What You Think!
You must be logged in to post a comment.