Claude Mythos was one of the most hyped models in recent memory. And it is out now. Sort of. Yesterday Anthropic launched Claude Fable 5, a generally available model built on the same weights as Mythos 5 that switches over to the older Opus 4.8 for most tasks that even mention cybersecurity or biology. Early feedback provided by Anthropic includes glowing reviews. Stripe said it compressed months of engineering into days, running a migration across a 50-million-line Ruby codebase in a single day. Physical Superintelligence called it the strongest model it has tested on frontier physics research while using a third of the reasoning tokens.
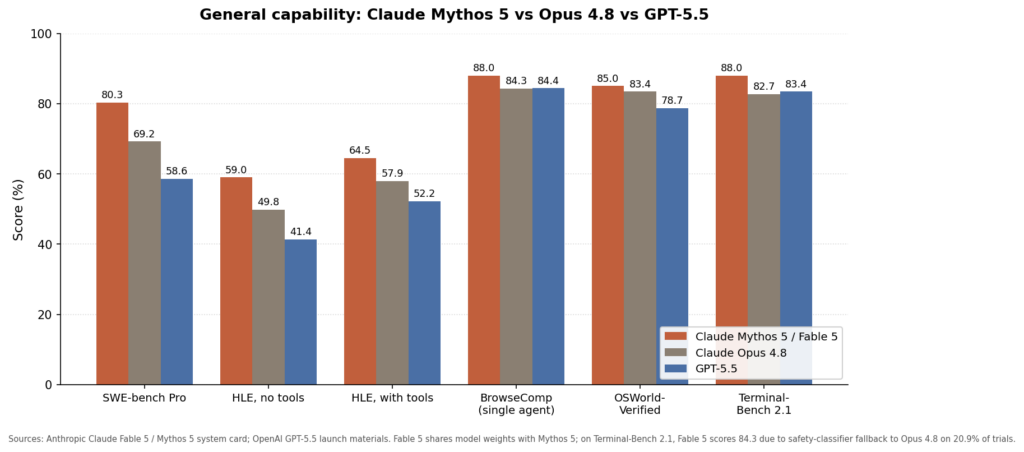
The benchmarks also indicate a capability shift that is more than other recent launches. On Artificial Analysis’s Intelligence Index, Fable 5 ranks scored 65, ahead of OpenAI’s GPT-5.5 at 60 and Google’s Gemini 3.1 Pro Preview at 57.
The most positive feedback is coming from people using it for Claude Code, long coding tasks, app-building, design iteration and complex workflows. A Hacker News commenter who had spent time with it across Claude Code, Claude.ai and Claude Code for web called it “a beast” and said it was handling difficult problems they had avoided for months.
The gain in performance also comes at a premium. Fable 5 is priced at $10 per million input tokens and $50 per million output tokens, roughly double Opus 4.8.
The model is apparently adept at a number of life sciences tasks. Using Mythos 5, Anthropic’s internal protein-design experts reported roughly a 10x acceleration in parts of the drug-design process. In one test the model chose binding sites, ran the design tools and recovered from its own failures without human help, matching or beating skilled operators. Nine of the 14 protein targets in that study yielded strong drug-design candidates Anthropic says it is now investigating. In a separate week-long run with only high-level human input, the model assembled single-cell data spanning 138 animal species and trained a custom model that outperformed a recently published model in Science at one-hundredth the size.
For life-sciences readers, the catch is that the drug-design and genomics capabilities Anthropic spent the most ink on belong to Mythos 5, reachable only through a trusted-access program that opens “in the coming weeks.”
OpenAI is rumored to launch a new model this months with a few leak-style posts citing Codex routing/log references, a possible iris-alpha codename and claims of a 1.5M-token context window.
Methodology note: Two harness changes affect comparisons with earlier reporting. Opus 4.8’s Terminal-Bench 2.1 score rose from 74.6 to 82.7 after Anthropic switched from the Terminus-2 harness to mini-SWE-agent, and OSWorld figures reflect a zoom-tool bug fix plus a max-tokens increase from 16K to 128K. On Terminal-Bench, Fable 5 hit a safety refusal on 20.9% of trials, which accounts for its 84.3 versus Mythos 5’s 88.0 despite identical weights. In terms of GPQA Diamond, Anthropic reports Mythos 5 at 94.1, describes the benchmark as saturated, and plans to stop reporting it. CyberGym appears only in the cyber comparison table.