Less than a month ago, OpenAI released GPT-5.1 but was quickly eclipsed by Google’s launch of Gemini 3.0, which overall outranked its benchmarks. Following that, Anthropic launched Opus 4.5, which also generally outclassed it. Hoping to regain its crown after a reported internal “code red,” OpenAI has launched GPT-5.2 today. The model has benchmark claims that, if independently verified, would represent a real leap in abstract reasoning and professional knowledge work, areas where the company had been losing ground to competitors.
The company boasted that the model was, in some respects, the new market leader: “GPT-5.2 Thinking is the best model yet for real-world, professional use.”
The December 11 release caps an intense six-week stretch that saw Google ship Gemini 3 Pro in mid-November and Anthropic counter with Claude Opus 4.5 on November 24. Bloomberg reported that OpenAI CEO Sam Altman declared an internal “code red” amid the competitive pressure, fast-tracking what had been internally codenamed “Garlic.”
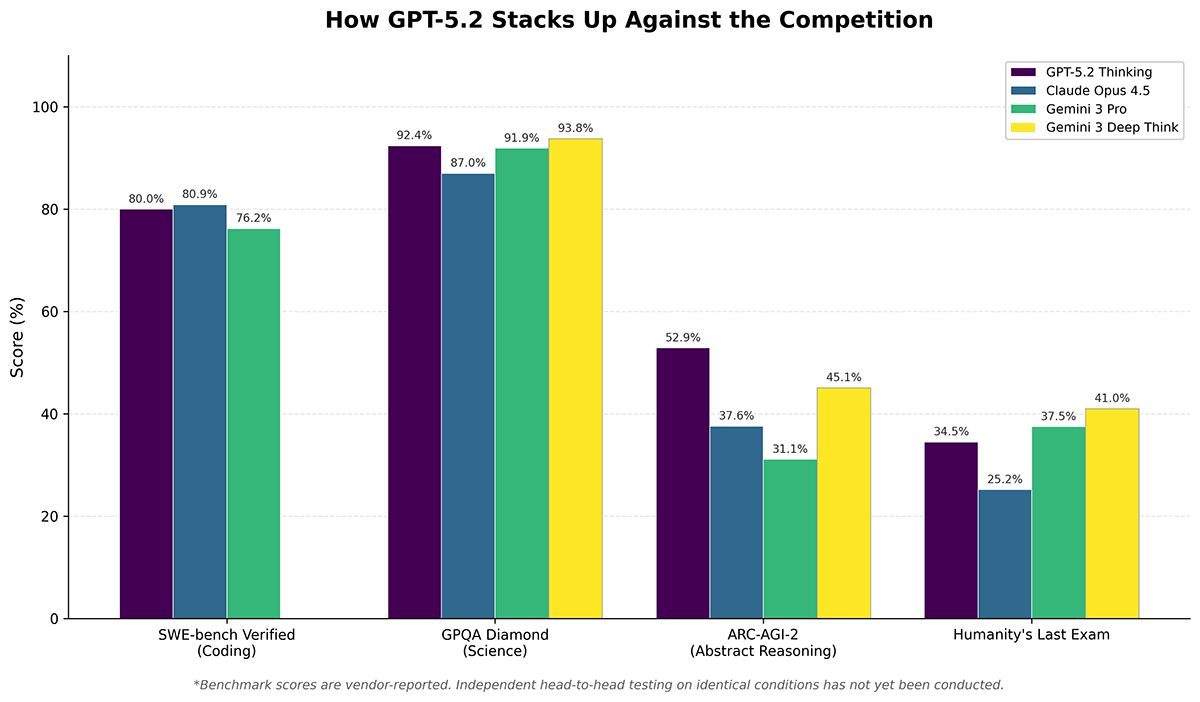
Here’s how the three frontier models compare across benchmarks most relevant to R&D applications, with the caveat that these are vendor-reported numbers pending independent verification.
The benchmarks at a glance
| Benchmark | GPT-5.2 Thinking | GPT-5.2 Pro | Claude Opus 4.5 | Gemini 3 Pro | Gemini 3 Deep Think |
|---|---|---|---|---|---|
| SWE-bench Verified (coding) | 80.0% | — | 80.9% | 76.2% | — |
| GPQA Diamond (science) | 92.4% | 93.2% | 87% | 91.9% | 93.8% |
| AIME 2025 (math, no tools) | 100% | 100% | ~94% | 95.0% | — |
| ARC-AGI-2 (abstract reasoning) | 52.9% | 54.2% | 37.6% | 31.1% | 45.1% |
| Humanity’s Last Exam | 34.5% | 36.6% | 25.2% | 37.5% | 41.0% |
| FrontierMath Tier 1-3 | 40.3% | — | — | — | — |
Note: Tilde (~) indicates estimated values from available data. Dash (—) indicates unreported scores.
Where GPT-5.2 claims leadership
The most striking claim is GPT-5.2’s performance on ARC-AGI-2, a benchmark designed to test genuine reasoning ability while resisting memorization. At 52.9% (Thinking) and 54.2% (Pro), OpenAI’s new model significantly outranks both Claude Opus 4.5 (37.6%) and Gemini 3 Deep Think (45.1%). The ARC-AGI benchmark has become a bellwether for abstract reasoning capability, the kind of fluid intelligence that matters for novel problem-solving in research contexts.
GPT-5.2 also achieves a perfect 100% on AIME 2025 without tools, matching what Gemini 3 Pro achieves only with code execution enabled. On GPQA Diamond, a graduate-level science benchmark, GPT-5.2 Pro scores 93.2%, essentially tied with Gemini 3 Deep Think’s 93.8%.
OpenAI is also pushing a new benchmark called GDPval, which measures performance on “well-specified knowledge work tasks” across 44 occupations. The company claims GPT-5.2 Thinking beats or ties industry professionals 70.9% of the time, at 11x the speed and less than 1% of the cost. This is OpenAI’s own benchmark, however, and hasn’t been independently validated.
Where the competition holds ground
Claude Opus 4.5 still holds the top score on SWE-bench Verified at 80.9%, though early results may be unstable. GPT-5.2’s 80.0% closes what had been a more significant gap. Anthropic’s model also leads on Terminal-bench 2.0 (59.3%), which tests command-line coding proficiency, and claims industry-leading resistance to prompt injection attacks.
Gemini 3 Deep Think maintains the highest published score on Humanity’s Last Exam at 41.0% without tools, a benchmark explicitly designed to challenge frontier AI systems. Google’s model also achieved gold-medal performance at the International Mathematical Olympiad and International Collegiate Programming Contest World Finals, suggesting strength in competition-level mathematical reasoning. The closest equivalent to Deep Think is OpenAI’s “Pro” mode for its models (not to be confused with its Pro subscription tier), which often chews over a question for up to a half hour before answering.