[OpenAI]
While AGI is a murky concept with variable definitions, OpenAI defines it, in essence, as autonomous systems that can best humans at most economically valuable work.
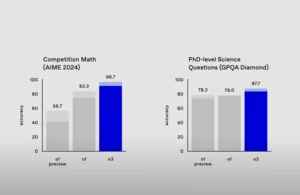
To be clear, The ARC Prize organization, which maintains the ARC-AGI benchmark, underscored that “passing ARC-AGI does not equate to achieving AGI,” noting that the model still “fails on some very easy tasks, indicating fundamental differences with human intelligence.” This statement has done little to stem a wave of speculation, partly because historically, GPT-family models scored near-zero or in the single digits on ARC-AGI. By contrast, GPT-3 scored 0% in 2020, and although GPT-4o managed 5% in 2024, Claude 3.5 Sonnet peaked at 14%, and o1-preview scored 18%. Now o3 has soared to the 75–88% range.
According to OpenAI, o3 achieved 87.7% on a set of ‘Google-proof’ doctoral-level science items, topping the previous o1 score of 78% and surpassing the roughly 70% typical of an expert Ph.D. in their own domain.
Some skeptics, however, have taken to LinkedIn to question the model’s reliance on the ARC-AGI-1 Public Training set, which has been publicly available on GitHub since 2019. A few observers compared AI’s “training set” to the human “practice” experience, framing it as legitimate, not mere brute force. Others highlight AI’s potential benefits in areas like medicine and fundamental science, emphasizing the upside despite potential dangers or misuse.
Gary Marcus, Ph.D., a cognitive scientist, entrepreneur, author and AI hype skeptic questioned openAI’s omission of data from other labs in their presentation on o3, potentially exaggerating its improvement relative to rivals. Marcus also notes that researchers wanted to see how an untuned version of o3 would perform to gauge the degree to which the ARC-AGI public training data proved instrumental to its performance while also underscoring the need for “significant external scientific review” to confirm what’s truly new or how robust it is while requesting that media ask “hard questions” regarding AI announces rather than perpetuate hype.
In any event, the 03 news has helped reframe the narrative that the broader genAI field was hitting a wall — eking out incremental performance gains with subsequent models when prior models often showed exponential improvements. The WSJ quipped, in an article dated December 20 — the same day o3 was unveiled — that “The Next Great Leap in AI Is Behind Schedule and Crazy Expensive.” But o3’s sudden leap in capabilities complicates that storyline.