In what Meta CEO Mark Zuckerberg called a “big upgrade,” Meta today unveiled its Llama 4 series of AI models, in an official announcement showcasing models that span extremes. Zuckerberg framed the launch with a clear objective: “Our goal is to build the world’s leading AI, open source it, and make it universally accessible so that everyone in the world benefits.” Meta is thus positioning this release as a significant step toward making leading AI models openly available, further challenging the dominance of closed systems after the emergence of DeepSeek R1. On the one hand is the openly available Llama 4 Scout, boasting what Zuckerberg calls an “industry-leading, nearly infinite, 10 million token context length” (equivalent to roughly 15,000 pages). That could support analysis of vast documents or codebases in a single pass without complex preprocessing like chunking. For comparison, OpenAI’s GPT-4o has a context window of 128,000 tokens.
TechCrunch reported that Meta appears to have used a customized version of Llama 4 Maverick specifically optimized for conversational tasks to achieve its high benchmark scores on LM Arena, while releasing a different “vanilla” version to the public.
A reasoning model is in the works. “The Llama 4 Reasoning model is being developed as a specialized model focused on enhanced logical capabilities and problem-solving,” Zuckerberg said.
I’m not aware of anyone training a larger model out there.
Meta also is previewing the nearly 2 trillion parameter Llama 4 Behemoth, positioned as a state-of-the-art “teacher” model used internally and to distill knowledge into the smaller models. Zuckerberg teased this massive model, stating, “This thing is massive – more than 2 trillion parameters. I’m not aware of anyone training a larger model out there. It is already the highest-performing base model in the world, and it is not even done training yet.” While Meta’s own announcements emphasize favorable, albeit sometimes selective, comparisons against rivals like GPT-4o, independent validation is emerging, with Llama 4 Maverick quickly securing a top spot (#2 upon release) on the Hugging Face Chatbot Arena leaderboard. Zuckerberg had previously expressed his belief that “open source AI is going to produce the leading models, and with Llama 4, this is starting to happen.”
Meta achieved its context window breakthroughs, particularly in Scout, through its “iRoPE architecture.” This approach uses interleaved attention layers without positional embeddings and employs inference time temperature scaling of attention to enhance length generalization. The “i” in iRoPE stands for “interleaved” attention layers, reflecting progress toward Meta’s long-term goal of supporting potentially “infinite” context length – aligning with Zuckerberg’s description of Scout’s “nearly infinite, 10 million token context length.”
[Behemoth] is already the highest-performing base model in the world, and it is not even done training yet.
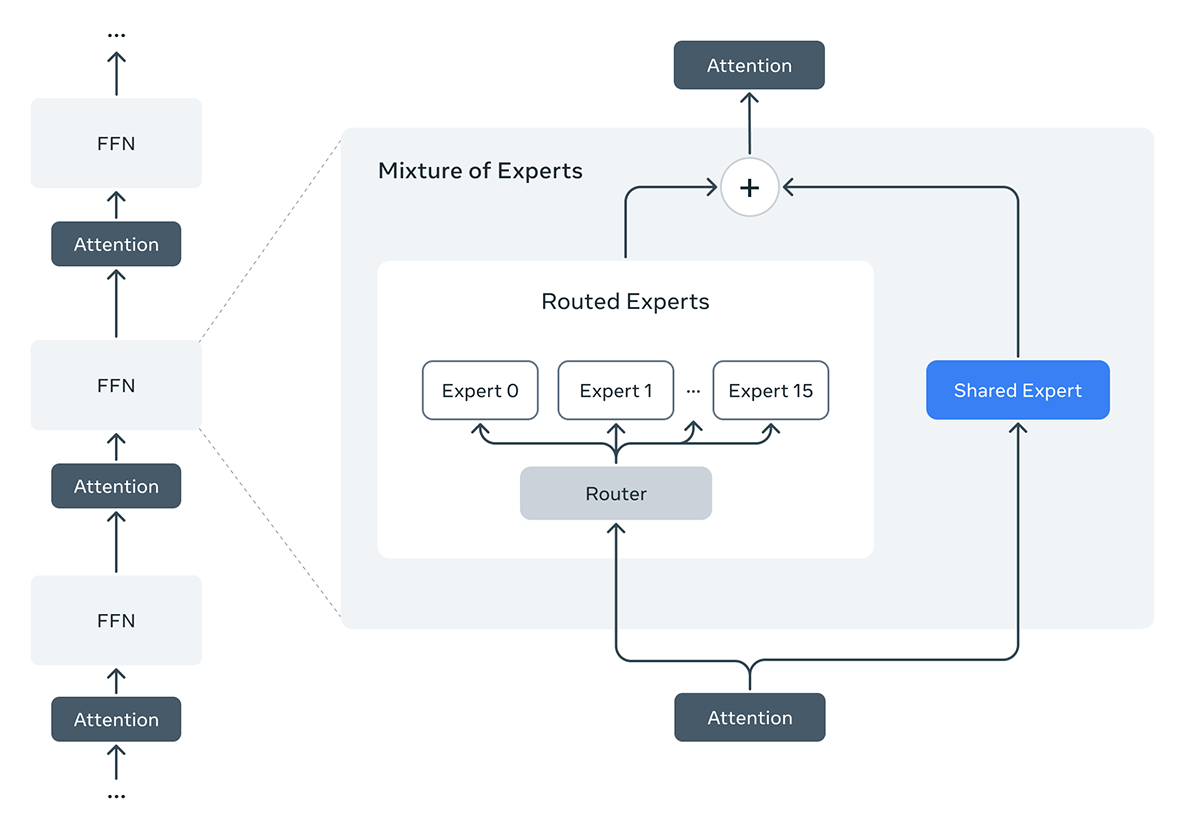
Parameter efficiency through mixture-of-experts
Both released Llama 4 models utilize a Mixture-of-Experts (MoE) approach, a key strategy for achieving high performance with computational efficiency. Llama 4 Maverick, for example, has 17 billion active parameters used per token, but draws from a vast pool of 400 billion total parameters spread across 128 experts plus a shared expert. As Zuckerberg noted for Maverick: “This one is 17 billion parameters with 128 experts.” In this architecture, each token activates only a fraction of the total parameters, achieving the performance associated with its massive total parameter count while only incurring the computational cost similar to its smaller active parameter count per token. This significantly improves inference efficiency and lowers latency compared to dense models of similar total size, as the company noted in an announcement and detailed in the official model documentation.
Maverick and Scout: distinct design philosophies within a diverse portfolio
Maverick’s high leaderboard ranking reflects Meta’s positioning of it as the flagship open model, designed as a powerful all-rounder competitive with top-tier proprietary systems. Zuckerberg dubbed it “the workhorse” and claimed, “It beats GPT-4o and Gemini 2.0 Flash on all benchmarks.” (Specs: 17B active/400B total parameters, 128 experts + shared). He added specific technical details: “It is smaller and more efficient than DeepSeek V3 but is still comparable on text.” Indeed, Meta claims Maverick matches the performance of the powerful DeepSeek V3 model on reasoning, coding, and multilingual tasks despite using fewer active parameters per token. Despite activating only 17 billion parameters per token via its MoE design, Meta claims Maverick outperforms key rivals on a range of coding, reasoning, and multilingual benchmarks. It supports a still-massive 1 million token context window (roughly 1,500 pages) and, like Scout, is “natively multi-modal,” capable of processing up to eight images alongside text for complex vision-language tasks and demonstrating strong coding and multilingual abilities (trained on circa 200 languages). Zuckerberg emphasized its deployment ease: “designed to run on a single host for easy inference. This thing is a beast.” More specifically, it’s designed to run efficiently on a single multi-GPU server (e.g., an Nvidia H100 DGX station with 8 GPUs), offering potential for significant cost savings compared to proprietary APIs (estimated ~$0.19-$0.49/1M tokens vs ~$4.38/1M for GPT-4 via API, according to some reports). Ideal for demanding tasks like advanced AI pair programming, enterprise document analysis, and sophisticated multimodal assistants.
Scout, meanwhile, prioritizes extreme context and efficiency. Its 16-expert MoE structure (17B active/109B total parameters), detailed by Zuckerberg as “17 billion parameters with 16 experts,” combined with the iRoPE architecture allows it to handle its industry-first 10M token context. This standout feature allows it to process enormous inputs like entire code repositories or books directly, a unique capability among current models. Zuckerberg highlighted its speed and accessibility: “It is extremely fast… and it is designed to run on a single GPU.” This high efficiency means it can run on a single high-end GPU (like an Nvidia H100 80GB) when quantized, making advanced AI accessible without large compute clusters. This makes it ideal for processing vast documents or codebases on limited hardware. While smaller, Meta claims it outperforms comparable models like Google’s Gemma 3 and Mistral 3.1 on relevant benchmarks. He concluded Scout is “by far the highest-performing small model in its class.” Perfect for long-context chatbots, summarizing lengthy documents, analyzing large codebases, or applications requiring decent performance on limited hardware.
Native multimodality through early fusion
A core architectural differentiator for the Llama 4 series is its native multimodality, achieved through an “early fusion” strategy. This aligns with Zuckerberg’s description of both Scout and Maverick as being “natively multi-modal.” This approach integrates text and vision processing into a unified backbone from the outset. This ‘early fusion’ strategy, integrating vision processing deeply within the model architecture from the start, potentially enables more nuanced and fundamentally integrated cross-modal understanding compared to approaches that simply add vision capabilities to text models. It thus contrasts with methods that append vision capabilities to predominantly text-trained models. By enabling joint pre-training across diverse datasets—including text, images, and significantly, video frames—Meta aims for a more fundamentally integrated cross-modal understanding.
The architecture incorporates an optimized vision encoder derived from MetaCLIP technology, reportedly tuned specifically for interaction with the language model components. Functionally, this translates to demonstrated capabilities such as handling multiple concurrent images (up to eight tested effectively) and sophisticated image grounding, particularly noted in Scout, which links textual queries precisely to visual regions. The ability to interpret temporal sequences from video frames further underscores the potential depth of this integrated approach. This represents a strategic architectural shift from prior Llama generations, potentially simplifying model development and enabling more nuanced multimodal applications than achievable with loosely coupled vision-text systems.
Raising the bar for open models
With the Llama 4 series, Meta significantly raises the bar for open-access AI models. They deliver unprecedented context length, competitive performance through efficient architectures, and robust multimodal capabilities. Zuckerberg summarized the achievement: “Overall, Llama 4 is a milestone for Meta AI and for open source. For the first time, the best small, mid-sized, and potentially soon frontier models will be open source.” While Behemoth remains an internal benchmark and ‘teacher’ model for now (reportedly outperforming models like GPT-4.5 and Claude 3.7 on several STEM benchmarks like MATH-500 according to Meta’s tests, though potentially rivaled by Google’s latest Gemini 2.5 Pro), and another model, “Llama 4 Reasoning,” focused on logic, is expected next month, the availability of the powerful Maverick and ultra-long-context Scout provides developers with compelling new tools. As Zuckerberg concluded, “There’s a lot more to do, but the trajectory here is clear. We’ve got more model drops coming soon, so stay tuned out there.” These releases are poised to accelerate innovation across the AI landscape.
Users wanting to interact with the new capabilities can do so immediately, as Zuckerberg pointed out: “If you want to try Llama 4, you can use Meta AI in WhatsApp, Messenger, or Instagram Direct, or you can go to our website at meta.ai.” Developers can access the open models (Scout and Maverick) via Meta’s GitHub repository and platforms like Hugging Face.


