[Adobe Stock]
On complex coding tasks, for instance, GPT-4.1 achieved 55% accuracy on the SWE-Bench verified benchmark, a big jump from GPT-4o’s 33%. Pokrass attributed this gain to focused improvements, stating, “[We’ve been working on] making it follow diff formats better, explore repos, write unit tests, and write code that compiles.” She highlighted the practical benefit of improved diff handling, explaining how tools like Aider use diff formats and “sometimes you want it to produce diffs… you save latency [and money] on the tokens that are not changed.” Still, this performance trails the leading scores on the same SWE-Bench test achieved by Google’s Gemini 2.5 Pro (63.8% with agent tools) and Anthropic’s Claude 3.7 Sonnet (62-63%). Furthermore, on advanced science and reasoning benchmarks like the GPQA (Graduate-Level Google-Proof Q&A), Google’s Gemini 2.5 currently maintains an edge, reportedly achieving state-of-the-art results where GPT-4.1 scored 66.3% on the difficult Diamond tier of questions.
Still, performance nuances exist depending on the specific coding task. For instance, an analysis by the code integrity platform Qodo, focused specifically on generating code suggestions for pull requests rather than the broader SWE-Bench task. IT found GPT-4.1 held a slight edge over Claude 3.7 Sonnet in its evaluation. Qodo noted GPT-4.1’s advantage stemmed partly from better adherence to task requirements and providing more contextually relevant suggestions in that specific scenario.
Considerable coding gains for 4.1 series
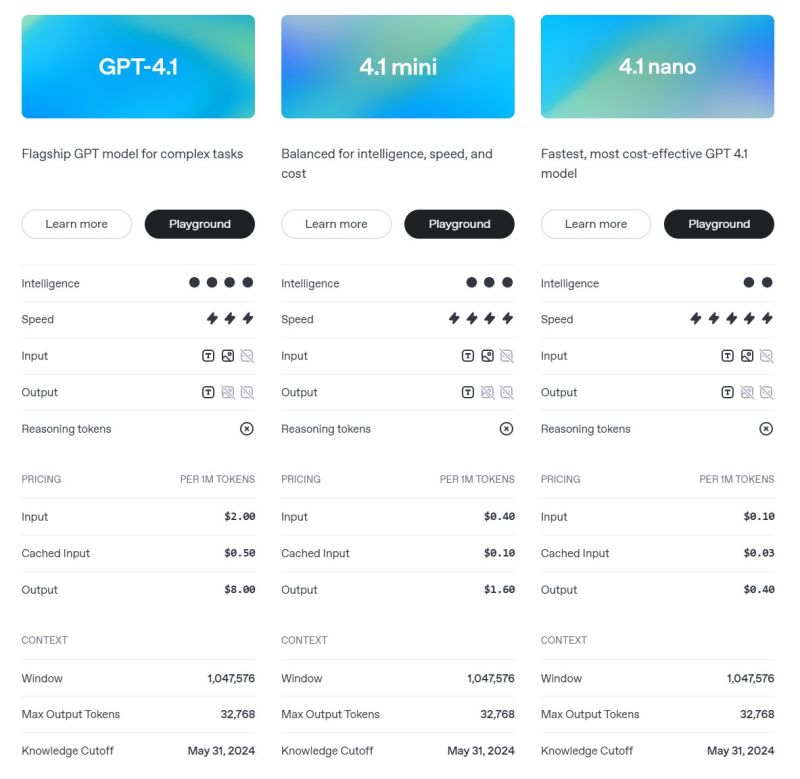
OpenAI positions GPT-4.1 as its “powerhouse for these three dimensions: coding, instruction following and long context,” according to Pokrass. Ishaan Singal, involved in Research at OpenAI, emphasized the reliability improvements, stating, “[We’ve] made the model way better at instruction following. It now strictly follows all the instructions that you provided.” He also noted that their internal testing reflects real-world usage: “[Our internal instruction following eval] mimics how an API developer uses our model.” GPT-4.1 also significantly expands OpenAI’s context capabilities, matching Google Gemini 2.5 Pro with a 1-million-token window—an eight-fold increase over the previous GPT-4o’s 128,000-token limit.
This larger window allows the API-exclusive model family (including the new mini and nano versions) to process and reason over extensive inputs like “entire codebases,” lengthy documents, or complex multimodal data such as videos. Alongside these technical improvements, OpenAI emphasized cost-effectiveness; the main GPT-4.1 model is 26% less expensive than GPT-4o via the API. During the launch event, Weil stated the aim is to “get GPT-4.1 out as broadly as possible.” While OpenAI now matches Google’s current 1 million token offering, Google has previously teased plans for a future 2 million token window for its Pro model.
Mini and nano variants
Beyond the main GPT-4.1 model, OpenAI also introduced GPT-4.1 mini and GPT-4.1 nano. According to Pokrass, “Nano is just an absolute workhorse for… tons of applications like autocomplete or classification,” offering the lowest latency and cost (reportedly 12 cents blended per million tokens) via the API. Despite its size and speed focus, it still achieved 80.1% on the MMLU benchmark. The mini version, meanwhile, provides a balance, with Pokrass noting it “really punches above its weight” and is likely the “top model… for multimodal or image processing.”
OpenAI’s strategic pivot toward a more efficient model mirrors its decision to phase out the compute-heavy GPT-4.5 preview. Weil explained the value derived from the deprecated 4.5 model, noting, “…a lot of the improvements [from 4.5]… are going to continue on in this model and in other models, so it has been a very successful experiment.” This aligns with CEO Sam Altman’s previous acknowledgment in an April post on X that integrating ambitious capabilities smoothly into GPT-5—once slated for a May release—is proving challenging, potentially delaying its arrival by several months. “We are going to be able to make GPT-5 much better than we originally thought. We also found it harder than we thought it was going to be to smoothly integrate everything, and we want to make sure we have enough capacity to support what we expect to be unprecedented demand,” he wrote. The launch of GPT-4.1 appears to something of a stepping stone. That is, it balances competitive multimodal capabilities and large-context processing at a lower price point, as OpenAI navigates intensifying competition from Anthropic and Google’s rapidly advancing Gemini series. Meanwhile, the differences between top-tier models are slim as the AI race continues to heat up. The Gemini 2.5. Pro model, for instance, has received widespread positive acclaim on social media in recent weeks — especially for its prowess in coding.