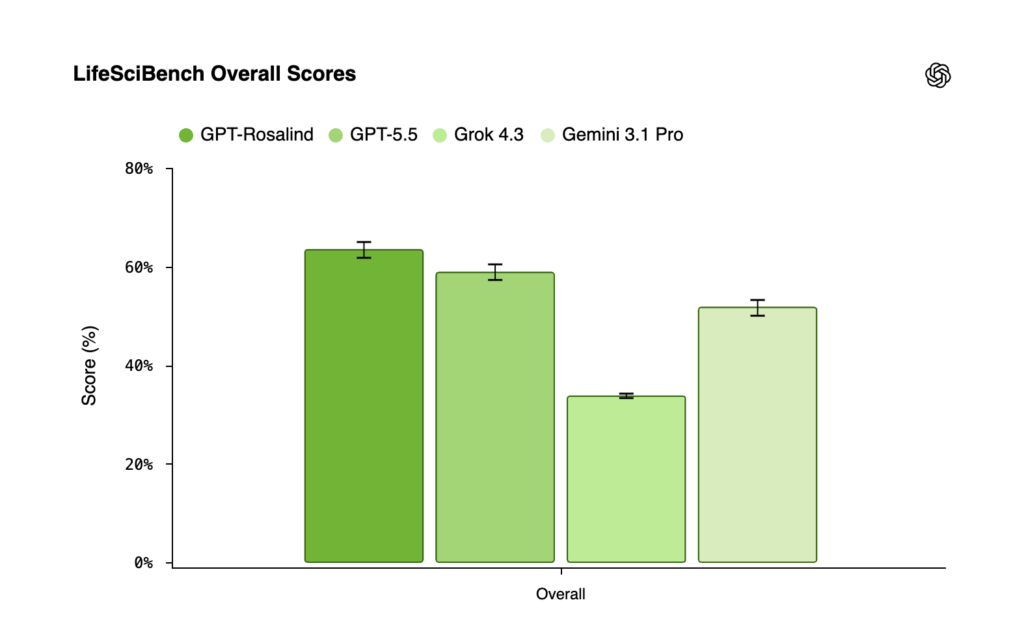
GPT-Rosalind bests other models on LifeSciBench, including GPT-5.5, Grok 4.3 and Gemini 3.1 Pro. The benchmark does not include Anthropic’s Claude models.
Solving humanity’s biggest problems has been OpenAI’s stated reason for pursuing artificial general intelligence since its 2015 founding, and over time, life science challenges have crystallized as core parts of its vision. In February 2025, CEO Sam Altman wrote that “we can now imagine a world where we cure all diseases,” and by that September he was suggesting that with enough compute, AI might figure out how to cure cancer.
The company has also forged partnerships with several players in the life sciences, with a 2024 Eli Lilly collaboration on antimicrobials and a deal with Sanofi and the startup Formation Bio on drug-development tools. An internal OpenAI for Science group followed in 2025. When GPT-Rosalind, its first model built specifically for the field, launched in April 2026, OpenAI named Amgen, Moderna, the Allen Institute, and Thermo Fisher Scientific as early partners.
The wider rollout follows a security-focused expansion OpenAI announced days earlier. On May 29, the company launched Rosalind Biodefense.
This week, OpenAI announced a broader Rosalind update that folds in GPT-5.5’s agentic coding and tool-use. The upgrade claims gains in medicinal chemistry, genomics, quantitative biology, and wet lab troubleshooting, with gains in Life Sciences Bench and MedChemBench. Access still runs through its trusted-access review.
OpenAI frames the update around LifeSciBench, an externally expert-judged benchmark it built to evaluate end-to-end scientific work across six workflow areas, including evidence handling, analysis, design and optimization, reasoning, validation and operations, and translation and communication. The company reports that GPT-Rosalind leads GPT-5.5, Grok 4.3, and Gemini 3.1 Pro on the overall score.
As part of the rollout, OpenAI named Novo Nordisk as a partner, framing GPT-Rosalind as a way to help the Danish drugmaker scale its medical research and connect evidence across areas spanning literature, genomics, transcriptomics, experimental results and beyond.
To learn more about the upgrades, R&D World reached out to OpenAI’s Joy Jiao, life sciences research lead, and Yunyun Wang, life sciences product lead.

Joy Jiao
All users can access the Life Sciences Research and NGS Analysis plugins in Codex, but only qualified enterprise users can power them with GPT-Rosalind. What changes when Rosalind powers the plugins versus the default model?
Joy Jiao: Rosalind will have deeper domain knowledge and expertise in biochemistry when interpreting specific results, but the workflows will run well with GPT-5.5.
Yunyun Wang: Users can expect higher performance on life sciences research tasks with GPT-Rosalind and expect more consistent results when used in combination with our Codex plugins as a combined execution and orchestration layer. We specifically track performance across the four capability areas outlined (medicinal chemistry, genomics and quantitative biology, lab assistance / wet lab troubleshooting and life sciences industry workflows). But users can expect strong usability and consistency across core workflows focused on biology database retrieval, data analysis, and next generation sequencing tasks with our two Life Sciences plugins with any OAI model.
Who designed and graded the benchmark rubrics, were the graders independent of OpenAI, and can outside groups reproduce any of the LifeSciBench, MedChemBench, GeneBench, or LabWorkBench scores?
Joy Jiao: Rubrics were designed by outside experts in their respective fields, and validated by a disjoint set of experts. Model outputs are graded by GPT-5.5 based on the expert-designed rubrics. We will be putting portions LifeSciBench, MedChemBench, and GeneBench on independent third party leaderboards to allow all frontier labs to use our benchmarks.

Yunyun Wang
In regulated work, pharma teams often keep generative models out of the deterministic path: for tasks like data translation, they have the model write code they can test and qualify rather than perform the conversion itself, since the standard is reproducibility and provenance. LabWorkBench scores Rosalind on wet lab troubleshooting directly. Where does a non-deterministic output fit when the validation bar is reproducibility?
Yunyun Wang: LabWorkBench is a reasoning evaluation based on changes real scientists have made to protocols, and tests the model’s ability to understand the underlying biochemistry and physical principles behind what makes or breaks experiments. Non-deterministic models are great at producing the deterministic workflows, writing tests, and inspecting outputs for quality and detecting deviations.