Conceptual image of AI from Google DeepMind via Pexels.
AI is being commoditized in front of our eyes. Months after a frontier release, rivals, often including open source variants, either match it in terms of benchmarks, or come close. Meanwhile, every R&D and IP team now has access to the same enterprise Copilot license, the same Claude and ChatGPT seats, the same general-purpose models their competitors are running. Access is no longer a differentiator. GenAI’s becoming a utility, like email or video conferencing.
So the real question for any R&D leader right now is “how are we making our AI less of a commodity?”
That’s perhaps the most important question. And most teams aren’t asking it.
At Cypris we work with hundreds of enterprise R&D and IP teams and thousands of researchers across pharma, advanced materials, aerospace, and consumer goods. The pattern is consistent everywhere we look. Teams are confusing access to AI with a real AI strategy. The gap between those two is where every ounce of competitive edge is going to come from for the next decade.
Here’s how the teams pulling ahead are closing that gap.
The commoditization and trust problem
| An artist’s illustration of artificial intelligence (AI). This image explores how AI can be for weather prediction. It was created by Dada Projects from Google DeepMind. Video hosted on Pexels. |
When your competitor signs up for the same LLM you did, your edge from that tool is gone. Copilot inside your company is the same Copilot inside the company trying to eat your lunch. Your researchers and their researchers are now running the same prompts against the same models and getting variations of the same answers.
Ask a general-purpose model a question about prior art and it responds with whatever context it was exposed to. For most deployments that’s a pile of internal documents, some web crawl, and a foundation model with no domain grounding. It doesn’t know what a patent family is. It doesn’t know how to weigh a USPTO filing against its EP equivalent. It doesn’t know that “Samsung” in a patent context might refer to one of forty different legal entities. It hallucinates, or worse, gives a confident answer based on unvetted web content. Either way, you can’t trust it for anything that matters.
AI is you get out what you put in. That cliché is the entire ballgame. The teams that understand this are spending less time on model selection and more time on the four layers below. That’s where AI stops being a commodity.
Layer 1: Verticalized agents built on R&D and IP data
The first move to de-commoditize your AI is to stop relying on general-purpose infrastructure for domain-specific work. You need agents that are verticalized and built on the foundation of R&D and IP data.
A few things matter here:
- The agent has to understand the data. A patent isn’t a document. It’s a structured object with families, priority dates, assignees, citations, legal status, and jurisdictional nuance. If your agent treats it like a PDF, your insights will be distorted from the first query.
- The data has to stay current. R&D and IP intelligence decays fast. A model trained on a static snapshot of the world is already wrong by the time it answers the question.
- The ontology and system prompt are not an afterthought. They’re the operating philosophy of the agent. They decide what it surfaces, what it ignores, and how it reasons through ambiguity.
Think about it like hiring. When you bring on a new researcher, you don’t hand them a laptop and point at a problem. You interview them. You figure out how they think. You watch how they handle edge cases before you let them represent the team in front of leadership.
An agent is no different. If you haven’t vetted its framework for how it sees the world, you can’t trust its decisions. Full stop. On top of that, you need to ensure that your agents, which have no stateful memory, stay grounded in your actual current operational needs.
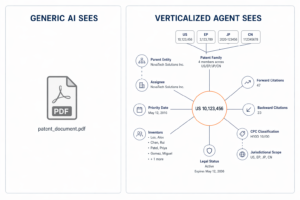
A conceptual example of how a verticalized agent views a patent versus an off-the-shelf model.
Layer 2: Workflow design as proprietary IP
This is where most teams are a year behind.
Take prior art search. Every IP team I’ve worked with has a different philosophy. Some go wide and cast across every jurisdiction. Some go narrow and focus on the top five markets. Some weigh non-patent literature heavily. Some don’t touch it. Most organizations have a tribal understanding of “what we already know” that lives in a senior attorney’s head and nowhere else.
A commodity AI tool can’t do any of this. It runs the same prior art search for your team that it runs for the team at your biggest competitor.
A verticalized agent configured to your workflow does the opposite. It knows your jurisdictions. It knows what your team has already cleared. It knows the output format your examiners expect. It knows your internal taxonomy of technology areas. It learns the way your organization thinks.
Here’s the part most leaders haven’t absorbed yet. How you design these agentic workflows becomes your organization’s proprietary IP. The prompts, the ontologies, the chained workflows, the feedback loops. That’s the asset. It’s a trade secret in the same way a proprietary synthesis route or a manufacturing process is. Three years from now, the teams that invested in this layer are going to look back and recognize it as the real investment. The teams that didn’t are going to be renting someone else’s.
Layer 3: Agents that work while you sleep
The third move is the one almost no one is executing on yet. It’s also the one with the biggest long-term payoff.
Most of the AI deployment conversation today is about agents that answer questions on demand. Useful, but reactive. The phase after that is monitoring. Agents that do work while you’re not looking.
We’ve been spending a lot of our time here lately. The pattern is simple in concept, hard in execution. An agent continuously watches the global patent, scientific literature, clinical trial, funding, and regulatory landscape. It knows what your team is working on. It knows what your competitors are doing. It surfaces threats and opportunities before they hit your desk as a problem.
An R&D director shouldn’t be running a new freedom-to-operate search every Monday morning. The agent should be running it continuously and flagging when something changes. An IP counsel shouldn’t be manually tracking a competitor’s prosecution history. The agent should flag the new filing the week it publishes. A portfolio lead shouldn’t be the last person to find out about a new entrant in an adjacent technology area.
This is where teams start to compound. Agents working async, on your domain, against your priorities, without a human having to kick them off every time. That’s the furthest thing from a commodity. That’s a proprietary research function running 24/7 against your strategic priorities.
Layer 4: Model-agnostic architecture
Here’s a detail that separates teams who ride the wave of AI progress from teams who get tied to one boat. Don’t build your strategy on top of a single model provider.
Foundation models are improving on a weekly cadence right now. One lab pushes on reasoning, another pushes on long-context synthesis, another on multimodal, another on cost. Open-source catches up in pockets and sometimes leapfrogs. The leaderboard is going to keep churning for years. If your entire AI infrastructure is welded to one provider, you’re locked into their roadmap, their pricing, their reliability, and their priorities. That’s the opposite of what you want.
The teams doing this right treat models as interchangeable components. The agent architecture, the data layer, the ontologies, the workflows stay constant. The model underneath gets swapped in and out based on what’s best for the task at hand. A reasoning task routes to one provider. A summarization task goes to another. A cheap classification task runs on an open-source model. Your team doesn’t have to care. They just see the output.
This is how you actually ride the wave instead of getting stuck on last year’s bet. When the inevitable price war happens, or a better model ships on a Tuesday, your organization captures the benefit immediately. You don’t replatform. You don’t retrain anyone. You switch.
There’s a subtler benefit to this architecture. It forces you to build the other layers correctly. If you know you might swap the model, you can’t cheat by burying critical logic inside a prompt. You have to put it where it belongs, in the ontology, the workflow, and the system design. Which is exactly where it should live anyway.
Model-agnostic architecture is also the answer to a question every enterprise should be asking their AI vendors right now: what happens to my investment if the model landscape shifts? If the vendor’s answer is “we’ll migrate you,” you’re already tied to one boat. If the answer is “your workflows and data don’t change, we just route to a different model,” that’s a vendor built for the next decade.
What this looks like in practice
A quick example from a Fortune 1000 customer we work with in the minerals space. Name omitted to preserve their privacy.
They’ve been running agentic monitoring across their entire R&D portfolio for the past year. Before, their team was spending the bulk of their week on data collection. Pulling filings, reading literature, tracking competitors, assembling landscape reports, stitching together spreadsheets. The strategic work, the part the team was actually hired to do, was getting squeezed into whatever time was left on Friday afternoon.
After deploying agents configured to their specific workflows and priorities, the ratio flipped. The team is now spending roughly 5x more time on strategic insight versus data collection. The agents do the surveillance work continuously. The humans do the thinking.
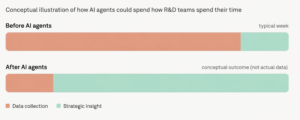
The monitoring agents surfaced a white-space opportunity in an adjacent technology area that the team hadn’t been actively watching. That insight turned into three new product lines this year. Separately, the agents flagged a pattern of IP activity from a smaller player in the space that turned into an acquisition target on their strategic roadmap.
Neither of those outcomes was possible with commodity AI because commodity AI wasn’t watching the right things, in the right way, against the right context. The strategic insight only happens when the agent layer is doing the unglamorous work of continuous monitoring, grounded in the organization’s actual priorities, against verticalized data the agent actually understands.
De-commoditized AI is fundamentally layer of infrastructure that’s producing strategic intelligence while people are focused elsewhere, and occasionally turning up opportunities that wouldn’t have been visible any other way.
The assessment for R&D and IP leaders

Steve Hafif
If you’re running an R&D or IP organization right now, a few things are worth being direct about.
A Copilot license is a productivity feature for the masses, including your competitors. Your moat is not the model. It’s the context, the data, and the workflows you wrap around it. The agent design work you do this year is the proprietary asset you’ll be glad you built in three years. The teams investing in verticalized, workflow-configured, continuously-monitoring, model-agnostic agents are going to compound. The teams treating AI as a chatbot license are going to fall behind and not understand why.
The next decade of R&D and IP work is going to be defined by how well teams build their agent layer. Commodity AI is table stakes. The real work starts after that.
Steve Hafif is the CEO and Co-Founder of Cypris, an AI-powered R&D and IP intelligence platform working with enterprise research teams across pharma, materials, aerospace, and consumer industries.