![]() Another week, another AI model drop (or maybe at least two). While OpenAI is rumored to imminently launch GPT-5, its much-delayed successor to GPT-4 that gave way to a smattering of successors, Anthropic has launched Claude Opus 4.1, which achieves a reportedly leading 74.5% score on SWE-bench Verified. For context, SWE-bench Verified is a 500-task, engineer-vetted subset of SWE-bench that scores models by the share of real GitHub issues they fully fix. In other words, it includes ensuring that a patch makes failing tests pass without breaking existing ones, in a containerized repo setup. While scores vary depending on the evaluation setup, the nearly 75% score is a notable improvement over the 72.5% for the prior version of Claude Opus 4, and represents the highest score in standard configuration—though when Anthropic launched Claude Sonnet 4, the firm noted that it achieved up to 80.2% when tested with parallel test-time compute. Still, compared to competitors, Opus 4.1’s score is approximately 21 points higher than the 53.6% score of Gemini 2.5 Pro.
Another week, another AI model drop (or maybe at least two). While OpenAI is rumored to imminently launch GPT-5, its much-delayed successor to GPT-4 that gave way to a smattering of successors, Anthropic has launched Claude Opus 4.1, which achieves a reportedly leading 74.5% score on SWE-bench Verified. For context, SWE-bench Verified is a 500-task, engineer-vetted subset of SWE-bench that scores models by the share of real GitHub issues they fully fix. In other words, it includes ensuring that a patch makes failing tests pass without breaking existing ones, in a containerized repo setup. While scores vary depending on the evaluation setup, the nearly 75% score is a notable improvement over the 72.5% for the prior version of Claude Opus 4, and represents the highest score in standard configuration—though when Anthropic launched Claude Sonnet 4, the firm noted that it achieved up to 80.2% when tested with parallel test-time compute. Still, compared to competitors, Opus 4.1’s score is approximately 21 points higher than the 53.6% score of Gemini 2.5 Pro.
Anthropic also notes that Opus 4.1 ups the game in AI-powered software engineering tasks while introducing improvements in agentic search, multi-file code refactoring and autonomous research capabilities. Released by Anthropic today, this incremental upgrade to Claude Opus 4 shows substantial performance gains across coding, reasoning and long-horizon task execution while maintaining its predecessor’s pricing at $15 per million input tokens and $75 per million output tokens, which is relatively high in the market. For instance, OpenAI’s non-reasoning GPT-4.1 is $2 per 1M input tokens and $8 per 1M output tokens, while Google’s Gemini 2.5 Pro runs $1.25–$2.50 per 1M input (depending on context size) and $10–$15 per 1M output versus Opus’s $15/$75.
Major technology companies including Rakuten Group, GitHub and Block have already integrated the model, reporting positive results in real-world applications ranging from 7-hour autonomous coding sessions to complex enterprise workflows.
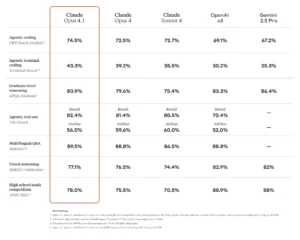
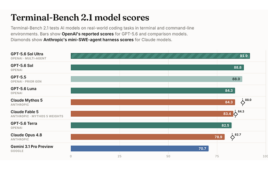
Anthropic claimed benchmarks for Opus 4.1. Image from Anthropic.
Rakuten Group, the Japanese tech conglomerate, reports the model “excels at pinpointing exact corrections within large codebases without making unnecessary adjustments or introducing bugs,” according to Anthropic.
Extended thinking capabilities enable Claude Opus 4.1 to tackle problems requiring deep reasoning. The model can chew through up to 64,000 tokens for complex thought processes, achieving 83.3% on GPQA Diamond (graduate-level physics) and 90% on AIME (advanced mathematics) when given sufficient thinking time. Other frontier models tend to score in the low‑to‑mid‑80s on GPQA Diamond and mid‑80s to low‑90s on AIME. For example, OpenAI’s o3 and Gemini 2.5 Pro both score around 83.3% and 83.0%, respectively, on GPQA Diamond, and Gemini scores about 83% on AIME versus Claude’s 90%.
Multi-file refactoring and coding precision gains
GitHub’s integration of Claude into Copilot highlights the model’s solid coding capabilities, with the company specifically noting “particularly notable performance gains in multi-file code refactoring.” This improvement addresses one of the most challenging aspects of software development: making coordinated changes across multiple files while maintaining code integrity and avoiding unintended side effects. Where previous models showed navigation error rates around 20%, Claude Opus 4.1 reduces this to near zero, according to Anthropic.
The precision improvements manifest in several key areas that developers value most. Block reports Claude Opus 4.1 as “the first model to boost code quality during editing and debugging,” while Cognition notes it “successfully handles critical actions that previous models have missed.”
Consumer to enterprise platforms availability
Claude Opus 4.1 is immediately available across multiple platforms. The consumer-facing Claude Code provides a command-line interface that grants full codebase awareness and autonomous execution capabilities.
Enterprise users can access Claude Opus 4.1 through established cloud platforms without regional restrictions or staged rollouts. Amazon Bedrock offers the model in US East (Ohio, N. Virginia) and US West (Oregon) regions with cross-region inference for automatic optimization. Google Cloud Vertex AI provides even broader geographic coverage including us-east5, europe-west4, and us-central1, with global endpoints in public preview for enhanced availability.
The API implementation (model ID: claude-opus-4-1-20250805) supports advanced features including prompt caching for up to 90% cost savings and batch processing for 50% reductions on asynchronous workloads.