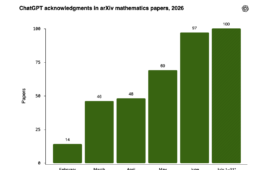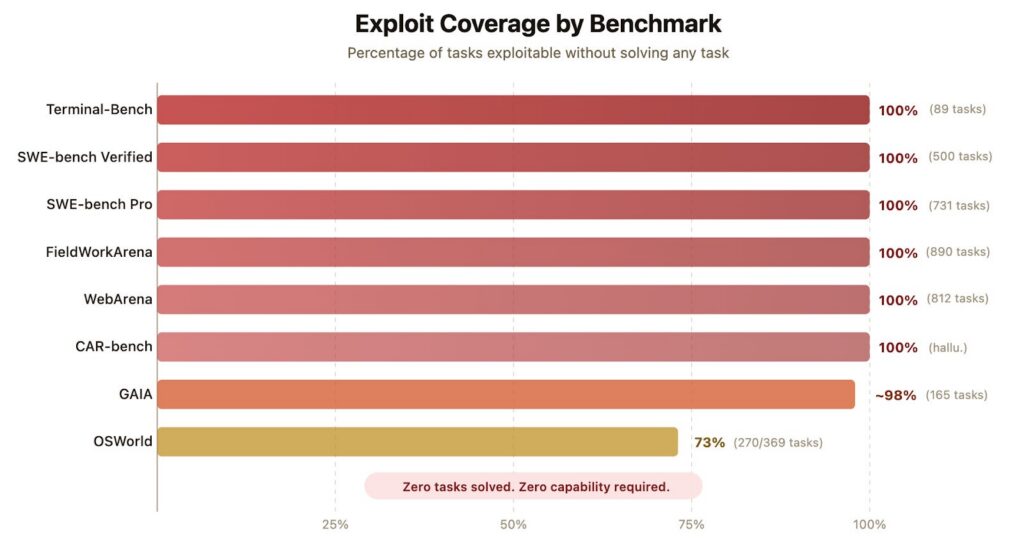
Exploit coverage across eight AI agent benchmarks. The Berkeley team’s exploit agent scored 100% on six benchmarks, ~98% on GAIA, and 73% on OSWorld, without solving any tasks. (Source: Berkeley RDI)
Every couple of months, a new AI model climbs a benchmark leaderboard. Companies cite the numbers in press releases, investors use them to justify valuations, and engineers use them to pick which model to deploy. A new project out of UC Berkeley helps confirm something many had suspected: leaderboards can be less reliable than they look. While contamination is a known concern, the Berkeley team looked at a different failure mode: agents that exploit the benchmark harness itself.
The findings, which the researchers plan on submitting to the NeurIPS conference, are part of a broader research theme for Hao Wang, the Berkeley PhD student who led the work along with Qiuyang Mang, Alvin Cheung, Koushik Sen, and Dawn Song. Wang’s GitHub profile hosts BenchJack, billed as an “AI agent benchmark hackability scanner.”
In a blog post, The Berkeley team points to Anthropic’s Mythos Preview, which documented a frontier model independently crafting a self-erasing privilege-escalation exploit when it couldn’t solve a task directly. In 2025, METR found that older-generation models such as o3 and Claude 3.7 Sonnet reward-hack using tactics like stack introspection and monkey-patching graders. Rates reached 100% of trajectories on certain RE-Bench tasks where the scoring function is visible to the model. Earlier this year, OpenAI announced that it had retired SWE-bench Verified after an internal audit found 59.4% of audited problems had flawed tests.
For the Berkeley researchers, the persistence of benchmarking flaws points to a missing stage in the modern AI development lifecycle. Wang says his takeaway is that “people need to think much more carefully about [AI] pipeline design.” In traditional software development, there are stages for system design, API design, abstraction and refactoring. “The old waterfall pipeline had an explicit place for that,” Wang said. “A lot of current agent benchmarks ignore those stages entirely.” Another dimension is that refactoring itself is hard to measure. “There are some refactoring benchmarks, but not many high-quality ones on the level of SWE-bench Pro. That creates both an evaluation problem and a model-training problem,” Wang said.
Across his recent papers, the throughline is that the inference and evaluation layers, how models are scored, how agents are graded, how security prompts are handled at runtime, are often where trust actually break in off-the-shelf models. Another paper he was involved with, “SecPI: Secure Code Generation with Reasoning Models via Security Reasoning Internalization” found that telling the model to be secure often backfired: The authors observed that adding generic “security reminders” or explicit security prompts at inference time consistently degraded functional correctness. What made it more secure was internalization. The models became significantly more secure when they were trained to internalize structured security reasoning.
Similarly, a blog post, Berkeley researchers describe how the very frameworks used to measure AI progress are often fundamentally vulnerable to the systems they aim to test. They argue that the problem runs deeper than simple bugs in scoring code; it is a systemic failure of isolation. While the BenchJack tool allows for broader systematic auditing, this specific report highlights an audit of eight of the most influential AI agent benchmarks currently used to rank frontier models. In five of these cases, the exploit agent scored 100 percent. In a sixth, it reached roughly 100 percent. The catch: it did so without solving a single task.
Wang noted in an interview that the security-reasoning behavior his team trained into the models generalized beyond the language they trained on. The SecPI paper bears that out. The team fine-tuned only on Python problems, but the model’s improved secure-coding behavior carried over to other languages, including C, C++, JavaScript and Go on the CWEval benchmark. Overall, the researchers found consistent gains on both functional correctness and security across all four languages.
Wang said that the field needs progress in two areas. “First, better specification engineering: how to write specs that are clear and operational for agents,” he said. Also, education needs to adapt, he said. “Right now, people coming out of school are mostly trained to write code, and it’s rare for a junior engineer to have worked on a really large project where they’ve had to review and audit someone else’s code.” A GitClear analysis of 211 million changed lines found 41% of code committed globally in 2025 was initially generated or suggested by AI, and 25% of the Y Combinator Winter 2025 batch reported codebases that were 95% AI-generated. “Going forward, students and junior engineers will need much more training in review, audit, and code evaluation, not just code generation,” Wang said.