
[Adobe Stock]
So how much more advanced is the Mythos tier, and where does the advantage actually live? Anthropic’s system cards point to a general-intelligence gap over Opus 4.8 that is modest and uneven, while the cyber gap is vast.
The Mythos gap is uneven
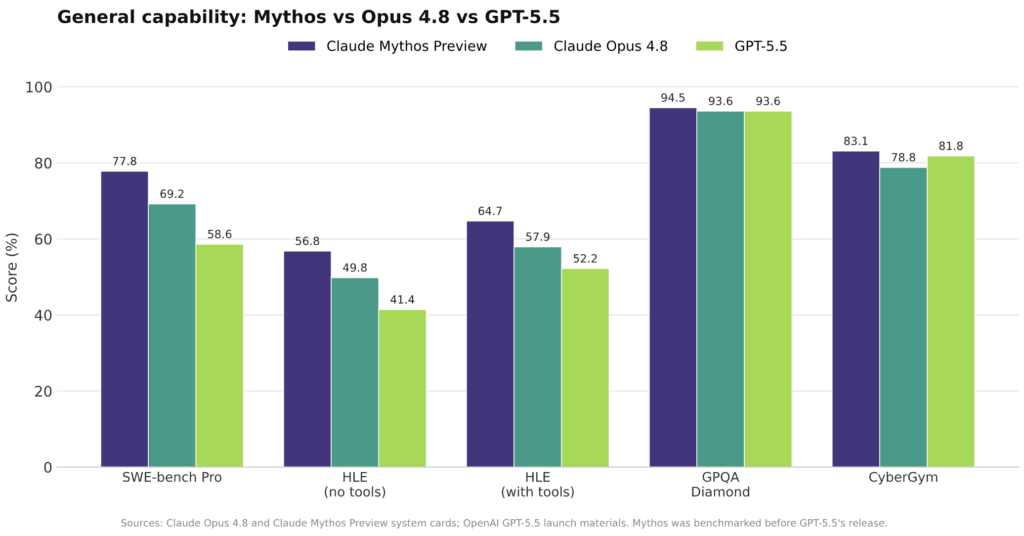
On Anthropic’s internal AECI index, Opus 4.8 lands at 155.5, between Opus 4.7 (154.1) and Mythos Preview (158.3), per the Opus 4.8 system card. Anthropic computed that on a small subset (n=11), so it reads as a few index points rather than a generational leap. Meanwhile, Mythos leads on the hardest software work, posting 77.8 to Opus 4.8’s 69.2 on SWE-bench Pro, a test of whether a model can resolve real GitHub issues in large codebases, and 59.0 to 38.4 on SWE-bench Multimodal, the same task with visual elements like screenshots and diagrams. The gap narrows on pure reasoning. GPQA Diamond, a set of graduate-level science questions written to be Google-search-proof, is a frontier tie at roughly 94, and the two models sit within a point of each other on USAMO, the US Mathematical Olympiad’s proof-based problems.
General capability
| Benchmark | Mythos Preview | Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 77.8 | 69.2 | 58.6 |
| HLE, no tools | 56.8 | 49.8 | 41.4 |
| HLE, with tools | 64.7 | 57.9 | 52.2 |
| GPQA Diamond | 94.5 | 93.6 | 93.6 |
| BrowseComp | 86.9 | 84.3 single-agent, 88.5 multi-agent | 84.4 |
| CyberGym | 83.1 | 78.8 | 81.8 |
| OSWorld / OSWorld-Verified | 79.6 OSWorld | 83.4 OSWorld-Verified | 78.7 OSWorld-Verified |
| Terminal-Bench | 82.0 on 2.0 | 74.6 on 2.1 | 78.2 on 2.1, or 82.7 on 2.0 |
Sources: Anthropic’s Claude Opus 4.8 system card for Opus 4.8 figures and Anthropic-reported GPT-5.5 comparisons; Anthropic’s Claude Mythos Preview system card for Mythos figures; OpenAI’s GPT-5.5 launch materials for GPT-5.5 rows omitted from the Opus 4.8 card. Benchmark versions and harnesses are not always identical. Mythos was benchmarked before GPT-5.5’s release, so Mythos figures were not originally reported head-to-head against GPT-5.5. Terminal-Bench and OSWorld rows should be read as directional because versions and variants differ.
Cyber is Where the leap lives
Anthropic’s own Opus 4.8 card states the model is much weaker than Mythos on cyber, and the internal evaluations are stark. With safeguards off, Mythos produced a full working exploit on 70.8% of Firefox targets against Opus 4.8’s 8.8%, and failed to score on only 23.3% of OSS-Fuzz targets versus 61.5% for Opus 4.8.
Why not include GPT-5.5-Cyber? GPT-5.5 complicates Anthropic’s framing. Berkeley RDI’s ExploitGym, the best public cross-model test so far, showed a significant lead for Mythos. ExploitGym paired Mythos with Claude Code against GPT-5.5 with Codex CLI across 898 real-world vulnerability instances. Mythos produced 157 intended working exploits to GPT-5.5’s 120, yet GPT-5.5 led on kernel exploitation, 22 to 12. The UK AI Security Institute found GPT-5.5 edging Mythos on expert cyber tasks, 71.4% to 68.6%, within overlapping uncertainty.
Cyber comparison, and how GPT-5.5 stacks up
| Cyber evidence | Mythos Preview | Opus 4.8 | GPT-5.5 | Read |
|---|---|---|---|---|
| CyberGym | 83.1 | 78.8 | 81.8 | GPT-5.5 is close to Mythos, Opus 4.8 trails |
| ExploitGym, intended working exploits | 157 of 898 | NA | 120 of 898 | Mythos leads, GPT-5.5 is strong |
| ExploitGym, total flags captured | 226 | NA | 210 | Gap narrows when unintended exploit paths count |
| ExploitGym, kernel exploits | 12 | NA | 22 | GPT-5.5 leads on this slice |
| AISI expert cyber tasks | 68.6% | NA | 71.4% | GPT-5.5 edges Mythos within uncertainty |
| AISI “The Last Ones” range, April test | 3 of 10 | NA | 2 of 10 | Mythos slightly ahead |
| AISI later testing, newer Mythos checkpoint | 6 of 10 on TLO, 3 of 10 on Cooling Tower | NA | 3 of 10 on TLO | Newer Mythos checkpoint reopens gap |
Sources: CyberGym, Firefox and OSS-Fuzz figures from Anthropic’s Claude Opus 4.8 system card; Mythos cyber context from Anthropic’s Claude Mythos Preview system card; ExploitGym figures from Berkeley RDI and the associated arXiv paper; AISI figures from the UK AI Security Institute’s GPT-5.5 cyber evaluation and its later autonomous cyber capability update. ExploitGym paired each model with a different agent harness and ran with safety filters disabled, so its results measure model-plus-agent-plus-access conditions rather than raw model capability.




Tell Us What You Think!
You must be logged in to post a comment.