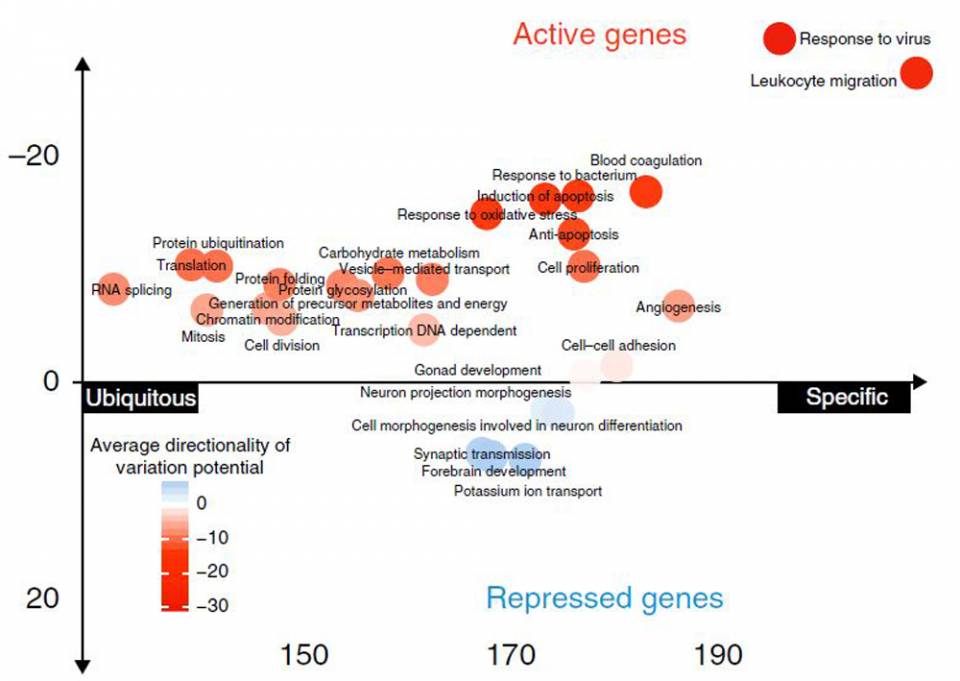
ExPecto identifies processes in blood cells that tend to be activated or repressed by mutations by analyzing predicted effects of mutations on tissue-specific gene expression. Image by the researchers
Genes produce proteins that keep your body functioning and healthy. But genes that code for protein make up less than 2 percent of your DNA. The rest of the DNA might appear to be dormant at first glance, but scientists now appreciate that this region plays a key role in turning genes on and off. Exactly how it does this has been an open question.
Now, researchers from Princeton University and the Flatiron Institute’s Center for Computational Biology in New York City have introduced a method to link variations in non-coding DNA to the operation of genes. Using machine learning, the researchers created a computational method, called ExPecto, that reads sections of DNA and predicts how that segment will alter the activation and deactivation of genes throughout the body.
Olga Troyanskaya, the principal investigator, said the system “can examine any genetic variant and predict its effect on gene expression.”
“That’s incredibly exciting,” said Troyanskaya, a professor of computer science and the Lewis-Sigler Institute for Integrative Genomics at Princeton and the deputy director of genomics at the Center for Computational Biology.
In a study published July 16 in the journal Nature Genetics, the researchers reported how they computed the effects of more than 140 million mutations on tissues throughout the body. The researchers identified mutations potentially responsible for increasing the risk of several immune-related diseases, including chronic hepatitis B virus (HBV) infection and Crohn’s disease. The researchers cautioned that their method is a long way from diagnosing disease; more work is needed to better understand the mechanisms of genetic operation and the balance between genetic and environmental causes of disease.
DNA contains genes that serve as blueprints for building proteins, the workhorse molecules of our bodies responsible for carrying out important tasks such as ferrying oxygen, communicating with other cells and fighting infections. Protein-coding sequences of DNA make up less than 2 percent of the human genome. All of these genes are present in cells throughout the body. This ubiquity means that protein-encoding genes vital to brain function, for instance, also exist in the digestive tract, lying dormant.
Genes are switched on and off by the other 98 percent of the genome, the noncoding portion that doesn’t code for proteins. Most genetic mutations are found in this noncoding region. A mutation is essentially a genetic typo — an addition, deletion or alteration in the genomic sequence. Mutations in the noncoding region can sometimes cause genes to switch on or off in the wrong part of your body at the wrong time, increasing the risk of diseases such as cancer.
Identifying the specific mutation responsible is difficult because the noncoding portion of DNA is so large. Previous studies compared the genomes of many individuals with a given disease, searching for mutations the individuals had in common. This approach, however, becomes increasingly tricky for rarer mutations. Furthermore, strings of DNA are sometimes inherited in large clusters, so scientists struggle to pinpoint which particular piece of genetic code is the troublemaker.
The study authors took a different approach. They developed ExPecto (named after the Patronus charm from the Harry Potter series) as a program that can read a raw sequence of DNA and predict the corresponding effect on gene expression.
ExPecto harnesses deep learning methods from artificial intelligence. Using a single reference genome, the researchers trained the program to understand how DNA controls gene expression across more than 200 different tissues and cell types. From this information, ExPecto can predict the effect of any mutation, even mutations that scientists have never seen before.
The researchers used ExPecto to predict the mutations that contribute to Crohn’s disease, chronic HBV infection and Behçet’s disease. Study co-author Chandra Theesfeld, a research scientist at Princeton, then experimentally verified the results. For all three diseases, she found that ExPecto’s predicted candidate was a more promising potential contributor to the disease than those proposed by previous studies.
The researchers hope that ExPecto will one day help medical experts identify the genetic contributors to a patient’s disease and develop therapies customized to the patient’s genome.
“Once you know which protein is affected and what the protein does, then you can design drugs that can fix the problem,” said study co-author Jian Zhou, a research fellow at the Center for Computational Biology. For instance, he said, “if you can’t produce a certain protein, then you could design a therapy that makes up for the missing protein.”
Anyone can access ExPecto’s predictions of the effects of more than 140 million possible mutations near protein-encoding genes. These results are available online as part of HumanBase, a data-driven prediction system about human biology and disease developed by the research team. Visitors can type in a gene and see all the potential mutations that could affect that gene’s expression in any of 218 tissues and cell types.
Zhou anticipates that ExPecto will be particularly insightful for studying the evolutionary consequences of mutations. He and his colleagues found, for instance, that mutations were less likely to affect genes expressed throughout the human body than genes specialized for one specific tissue type. “We don’t have a full explanation yet,” he said, but the result could be related to the robustness of more ubiquitous genes. An issue with a body-wide gene can have a higher likelihood of being fatal or otherwise preventing the individual from passing on his or her genetic information. “Evolution has already done the experiments for us,” Zhou said.
Warning: Cannot modify header information – headers already sent by (output started at /app/docroot/includes/common.inc:2777) in /app/docroot/includes/bootstrap.inc on line 1486



