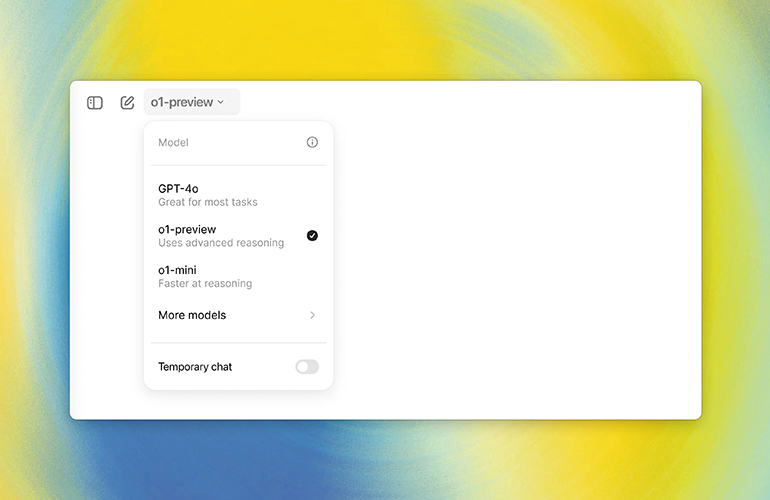
[OpenAI]
Unlike earlier predecessors, the o1 series is trained to mimic human thought, spending more time analyzing input before generating responses.
The current model can handle text only rather than OpenAI’s multimodal models.
A promotional video from OpenAI says that the code can succeed at coding more sophisticated programs, including games with multiple elements. For instance, o1 successfully generated code for a simple game called ‘Squirrel Finder,’ a task that previous models struggled with owing to its complex requirements. The game design involved character movement, object spawning, collision detection, and win conditions.
In coding competitions on Codeforces, an o1 model secured a place in the 89th percentile.
OpenAI also says that the o1 update performs comparably to Ph.D. students in challenging physics, chemistry, and biology benchmarks. The company says that it demonstrates strong proficiency in math, achieving an 83% success rate on an International Mathematics Olympiad qualifying exam. Conversely, GPT-4 achieved a 13% in the same benchmark.
Today also saw the release of Google’s DataGemma, a set of open models designed to tackle the issue of “hallucinations” in large language models. DataGemma makes use of Google’s Data Commons repository to ground LLMs in real-world statistical data to support more accurate AI-generated content.