
View of the ATLAS detector during July 2007. (Credit: Claudia Marcelloni, Courtesy of ATLAS Experiment, CERN)
At CERN, the European Organization for Nuclear Research, physicists and engineers are probing the fundamental laws of the universe using the Large Hadron Collider (LHC), the world’s largest and most powerful particle accelerator. The LHC collides protons and researchers measure the aftermath to test the predictions of the Standard Model, which has been the leading theory of particles and their interactions over the past 60 years. Scientists also hope to see hints of new physics processes. Particle collision experiments produce large amounts of data. Research at the LHC will generate around 50 petabytes (50 million gigabytes) of data this year that must be processed and analyzed to aid in the facility’s search for new physics discoveries.
The amount of data processed will grow significantly when CERN transitions to the High-Luminosity LHC, a facility upgrade being carried out now for operations planned in 2026. “With the High-Luminosity LHC, we’re expecting 20 times the data than what will be on disk at end of 2018,” said Taylor Childers, a computer scientist at the U.S. Department of Energy’s (DOE) Argonne National Laboratory and a member of the ATLAS experiment, one of the four major experiments at the LHC. “Based on our best estimates, we’ll need about a factor of 10 increase in computing resources to handle the increased amount of data.”
To help meet the LHC’s growing computing needs, ATLAS is working in conjunction with the Argonne Leadership Computing Facility (ALCF), a U.S. Department of Energy (DOE) Office of Science User Facility, located at Argonne National Laboratory. ALCF helps accelerate the pace of discovery and innovation by providing supercomputing resources that are 10 to 100 times more powerful than systems typically used for scientific research.
Argonne scientists are optimizing ATLAS simulations on the ALCF’s Intel-Cray supercomputer, Theta, to improve the processing efficiency on supercomputing resources. “By enabling a portion of the LHC grid’s workload to run on ALCF supercomputers, we can speed the production of simulation results, which will accelerate our search for evidence of new particles,” Childers said.
In addition, the Argonne team is optimizing the ATLAS workflows and software code to enable efficient use of Intel Xeon Phi processors and reduce bottlenecks in ATLAS project data processing. “We are developing a new workflow for supercomputers that increases the time spent simulating events by 20% on Theta nodes. We proposed simulating 1.3B events for ATLAS in the 2018-2019 ALCC time period based on current performance so a 20% improvement would get us to 1.5B events,” states Childers.
Particle Collisions in the ATLAS Detector
The ATLAS particle detector is located in a cavern 100 meters below the French-Swiss border near Geneva, Switzerland. The detector observes signatures of massive particles which were not observable using earlier lower-energy accelerators. Research covers a wide range of physics, including the discovery and study of the Higgs boson, searching for evidence of extra dimensions and particles that could make up dark matter, and understanding fundamental questions like why is the Universe made of matter and not anti-matter.
The ATLAS detector generates a petabyte of data a second with about 25 megabytes per event (raw; zero suppression reduces this to 1.6 MB) multiplied by 40 million beam crossings per second in the center of the detector. The trigger system uses simple information to identify, in real time, the most interesting events to retain for detailed analysis to make the data storage manageable.
The ATLAS experiment records the aftermath of colliding protons. The particle interactions happen in such a small space that only the outgoing debris is recorded by detectors. You can think of each recorded image in the detector as observing the site of a devastating car crash, with parts spread around and barely any whole cars left. The location and distribution of the parts must be analyzed to recreate the make and model of the cars involved in the collision.
Figure 1 shows a graphical representation of the ATLAS detector at CERN’s Large Hadron Collider, showing particles produced in the aftermath of the collision between two high-energy protons (the truck shown in lower left is depicted for scale). Several billions of these kinds of events have been simulated on ALCF supercomputers.
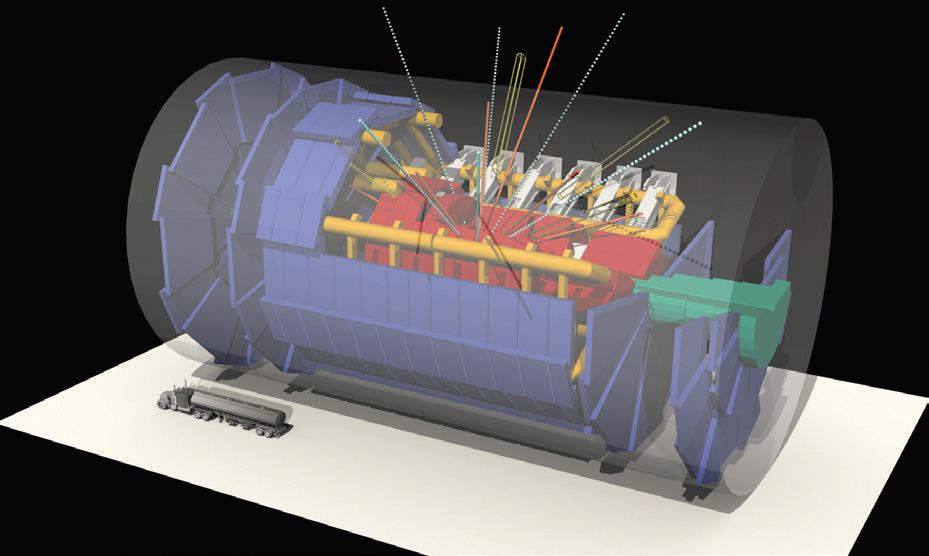
Figure 1. Simulation of ATLAS particle collision. (Credit: Courtesy of Taylor Childers, Joseph A. Insley, and Thomas LeCompte at Argonne National Laboratory.)
Putting the Theta Supercomputer to the Test
Theta is a massively parallel, 11.69-petaflop system based on Intel Xeon Phi processors. Theta features high-speed interconnects, a new memory architecture, and a Lustre-based parallel file-system all integrated by Cray’s HPC software stack. Theta’s parallel file system has a 10 petabyte capacity.
The Theta system is equipped with 4,392 nodes, each containing a 64 core processor with 16 gigabytes (GB) of high-bandwidth in-package memory (MCDRAM), 192 GB of DDR4 RAM, and a 128 GB SSD. Theta’s deeper, higher bandwidth memory hierarchy improves performance of big data applications compared to traditional supercomputers. In addition, the Xeon Phi architecture offers improved single thread performance and vectorization with Intel© AVX-512.

The Theta supercomputer. (Image: Courtesy of U.S. Department of Energy via Argonne National Laboratory)
Optimizing ATLAS Workflows and Code to Meet Increased Data Processing Needs
Experimental facilities, such as CERN, often use systems made up of small clusters to run their research. The computing requirements of CERN experiments led to the creation of the Worldwide LHC Computing Grid (Grid for short), which is composed of hundreds of clusters located at Universities and Laboratories around the world. However, the increase in data expected over the next decade at CERN is outpacing the growth in Grid resources.
The ATLAS work to utilize Theta is a collaboration between Argonne, Berkeley, Brookhaven, and SLAC (Stanford Linear Accelerator Center). ALCF is helping streamline simulation workflows through an allocation from the ALCF Data Science Program (ADSP), a pioneering initiative designed to explore and improve computational and data science methods that will help researchers gain insights into very large datasets produced by experimental, simulation, or observational methods. The ADSP team is collaborating with ATLAS to migrate and optimize the ATLAS research framework and production workflows to run on Theta. The goal is to create an end-to-end workflow on ALCF computing resources that is capable of handling the ATLAS experiment’s intensive computing tasks—event generation, detector simulations, reconstruction, and analysis.
LHC research software runs primarily on grid-style machines that are roughly a farm of desktop computers that do not communicate with one another. In this scenario, data is processed by running on a single compute node at a time. This leads to code behaviors that do not take full advantage of the capabilities of supercomputers and lead to poor performance. The team has modified ATLAS workflows to improve efficiency on supercomputers and their shared systems. This required adapting the workflows to the HPC environment, being able to run jobs in parallel on many nodes, sharing data, and retrieving data across multiple nodes.
The ATLAS software, named Athena, is a C++ framework for event processing which handles database access, data reading and writing, and other services. It has an event loop which processes one proton collision at a time. In the current workflow, each thread of a compute node processes events independently and is followed by a serial step to recombine the outputs from each thread into a single output. This serial processing cannot begin until the last thread on a node finishes event processing which results in idle CPU cores. ATLAS researchers are working on a new workflow, called the Event Service, that will run on Theta, which writes each event to the shared file-system where they can be uploaded to the grid for downstream processing. This keeps all threads processing till the job ends.
“Early testing of these new ATLAS features shows a 20 percent improvement in terms of how much processing time is saved. This means that in a year, the ATLAS code and workflow improvements might allow researchers to simulate between 150 and 250 million more events on ATLAS,” states Childers.
The ATLAS collaboration is working on a multi-threaded version of ATHENA that will collect multiple events and process similar calculations together as a single operation to improve the ability to take advantage of vectorization on CPUs, graphics processing units (GPUs), and other specialized architectures.
In addition, this work will improve the use of other supercomputers such as Cori at the National Research Scientific Computing Center (NERSC), which are already being utilized by ATLAS for simulating collisions.
Challenges for Future High-Energy Physics Research
“In ten years, the only computing resources capable of meeting the factor of 10 increase in LHC data processing needs will be supercomputers. Machine and deep learning techniques will also be big players in high-energy physics in the next 15 years. However, the computational cost of training deep networks is significant. There are many ongoing studies into using deep learning to identify specific particle signatures in a collision. These kinds of ideas are what our team is working on and hold great potential for the future of CERN LHC processing and high-energy physics research,” states Childers.
References
ALCF Data Science Program (ADSP): https://www.alcf.anl.gov/alcf-data-science-program
https://en.wikipedia.org/wiki/ATLAS_experiment
http://collider.physics.ox.ac.uk/atlas.html
https://www.youtube.com/watch?v=qQNpucos9wc
Linda Barney is the founder and owner of Barney and Associates, a technical/marketing writing, training and web design firm in Beaverton, OR.



