The jagged frontier of AI, where performance is divided harshly between peaks and valleys.
Stanford HAI’s 2026 AI Index paints a split-screen picture for R&D. In the report’s science chapter, “frontier models outperform human chemists on average on ChemBench,” yet “score below 20% on replication in astrophysics and 33% on Earth observation questions.” In medicine, the report reaches a similarly mixed conclusion, saying AI is transforming clinical care, but “rigorous evidence remains limited”: a review of more than 500 clinical AI studies found that nearly half relied on exam-style questions rather than real patient data, and only 5% used real clinical data.
The Index frames this pattern as a “jagged frontier,” drawing from a concept that has gained steam in recent years to refer to AIs’ ability to get more intelligent in areas such as coding and scientific reasoning while struggling with common sense.
Stanford HAI illustrates the fact that AI models can now earn gold-medal-level math results, with one variant of Gemini Deep Think scoring 35 points (42 is highest possible) at the 2025 International Mathematical Olympiad, while still failing to read analog clocks reliably. On ClockBench, the top model read analog clocks correctly just 50.1% of the time, versus 90.1% for humans.
The unevenness sometimes results in viral edge cases. In February 2026, a prompt asking leading models whether to walk or drive to a car wash 50 meters away spread online because many systems missed the implicit requirement that the car also has to arrive. A systematic test by Opper across 53 models found that 42 said to walk on a single run. A later preprint from Yubo Li and colleagues, “The Model Says Walk: How Surface Heuristics Override Implicit Constraints in LLM Reasoning,” formalized the pattern. The document found that in six open-source models the distance cue outweighed the car-washing goal by a factor of 8.7 to 38. IBM Think, meanwhile, argued that the episode says as much about intent ambiguity and how LLMs generalize from patterns as it does about raw reasoning ability.
A similar pattern played out with time. In a clip that later reached OpenAI CEO Sam Altman on the Mostly Human podcast, TikTok creator @huskistaken asked ChatGPT’s voice mode to time a mile run, stopped it seconds later, and got back a confident “10 minutes and 12 seconds.” Altman called it a “known issue,” said the voice model lacked the tools to start a timer, and estimated it might take “maybe another year” to fix.
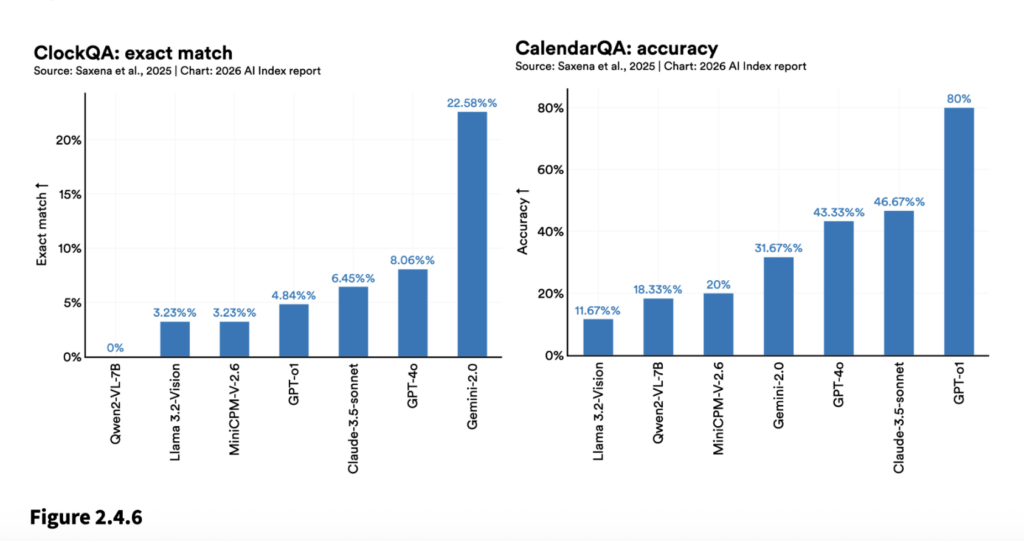
Figure 2.4.6 from The 2026 AI Index Report / Stanford HAI
GPQA, short for Graduate-Level Google-Proof Q&A, is one of the report’s better examples of why Stanford HAI says the frontier is jagged. The benchmark is meant to test hard, graduate-level science questions that require multi-step reasoning rather than recall. The report says model accuracy rose above an expert human validator baseline of 81.2%, hitting 93% in 2025. That strength now shows up across several demanding settings: top models came within 0.4 percentage points of the best human expert reference on MMMU, a multimodal benchmark built around diagrams, charts, tables and equations. The report says frontier systems also “outperform human chemists on average” on ChemBench.
In science, Stanford HAI says the best systems still score below 20% on ReplicationBench, a benchmark for paper-scale astrophysics replication. On PaperArena the top multi-agent setup reached 38.8% accuracy against an 83.5% baseline for Ph.D. experts. The gap is not simply about intelligence in the abstract. It is about whether that intelligence remains reliable once the task expands from answering questions to doing research.
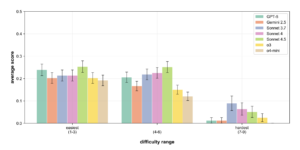
Unweighted ReplicationBench scores across tasks binned by difficulty. Performance reflects the agents’ ability to maintain faithfulness and correctness across varied scientific challenges. Source: Ye et al. (2025), ReplicationBench: Can AI Agents Replicate Astrophysics Research Papers? arXiv:2510.24591.
That unevenness shows up in biology as well. While biomedical datasets are getting bigger, bigger isn’t always better. The Stanford HAI AI Index notes that in molecular biology, smaller AI models are sometimes outperforming much larger ones: MSA Pairformer, a 111-million-parameter protein language model, beat previous leading methods on ProteinGym, while GPN-Star, a 200-million-parameter genomics model, outperformed a model nearly 200 times larger. For research teams, that is a useful corrective to the idea that progress in scientific AI will come mainly from ever-bigger general-purpose systems.
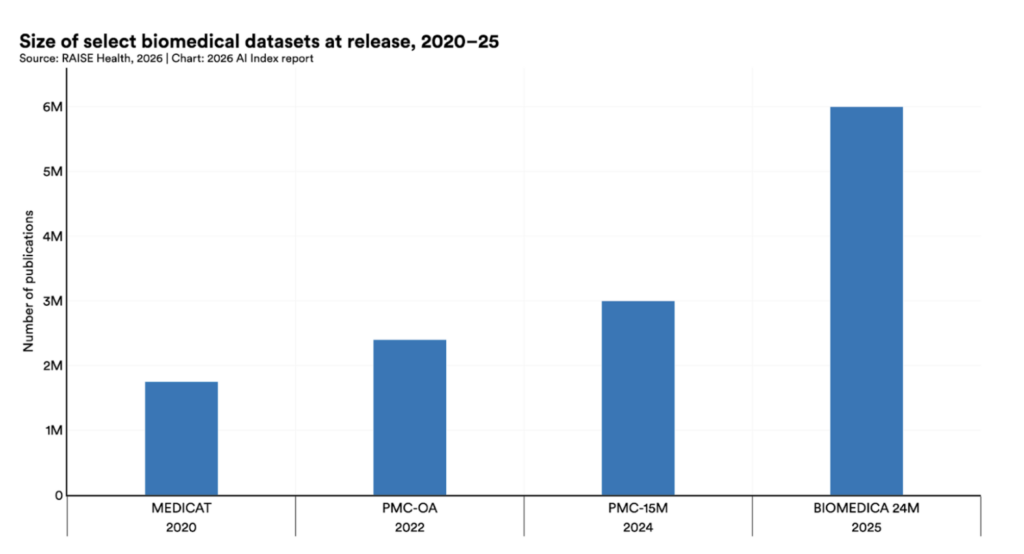
Figure from Stanford HAI’s 2026 AI Index Report.
In medicine, the report says AI tools that automatically generate clinical notes from patient visits saw substantial adoption in 2025, with physicians in some health systems reporting up to 83% less time spent writing notes and meaningful reductions in burnout. But Stanford HAI pairs that practical progress with a warning that the broader clinical evidence base remains thin. It notes that nearly half of more than 500 clinical AI studies relied on exam-style questions rather than real patient data, and that only 5% used real clinical data. In other words, AI is moving fastest where it can slot into existing workflows, and much more slowly where it has to clear a higher bar of clinical validation.