Anthropic, a favorite frontier AI lab among many coders and genAI power users has unveiled Claude 3.7 Sonnet, its first “hybrid reasoning” AI model. It is capable of both near-instant answers and in-depth, step-by-step reasoning within a single system.
Users can toggle an extended thinking mode where the model self-reflects before answering, considerably improving performance on complex tasks like math, physics and coding. In early testing by the author, the model largely succeeded in creating lines of Python (related to unsupervised learning) that were close to 1,000 lines long that ran without error on the first or second try, including the unsupervised machine learning task shown below:
 How “extended thinking” transforms AI problem-solving
How “extended thinking” transforms AI problem-solving
Claude 3.7 follows a trend made popular by OpenAI that is also a core functionality in DeepSeek R1 and in the “Think” mode of xAI’s Grok3 and several recent Gemini models — test‐time compute. In other words, the process allocates extra processing during inference to “think through” complex problems. OpenAI announced the approach publicly with the release of o1‑preview on September 12, 2024, and then launched the full o1 model on December 5, 2024.
Claude 3.7 builds on that precedent but is unique in being a hybrid model that can use extra “thinking” when needed. In standard mode, Claude 3.7 acts like a faster, upgraded Claude 3.5. In extended mode, the model tackles harder problems with careful reasoning, using up to 128K tokens internally to formulate better answers.
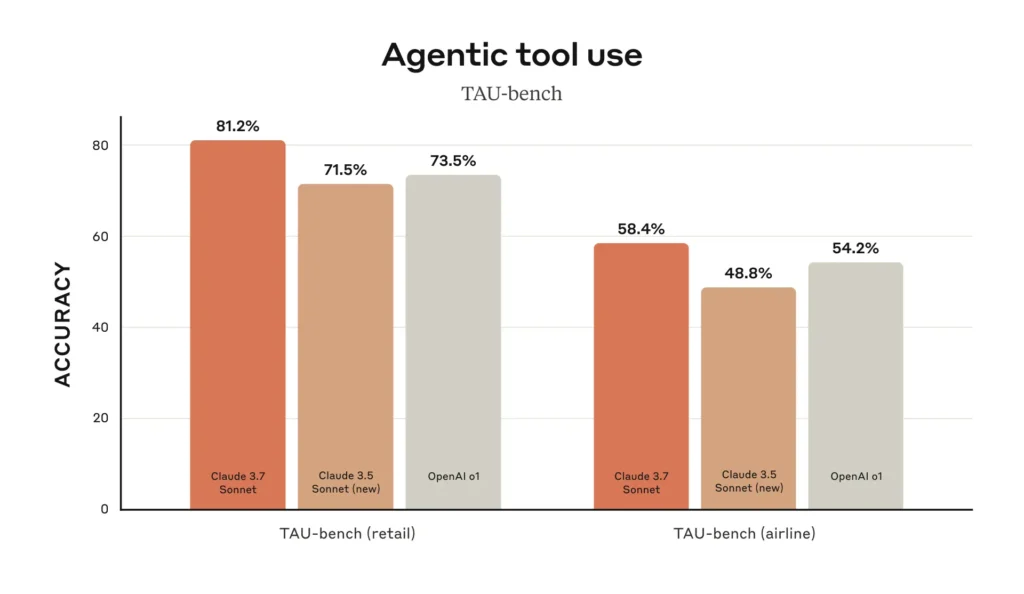
In an announcement from Anthropic partner AWS, the company noted that early customers using Claude 3.7 Sonnet “reported the biggest gains in math, physics, competition coding, and in-depth analysis when using extended thinking,” according to Vasi Philomin, VP of Generative AI, AWS.
[Image courtesy of Anthropic]
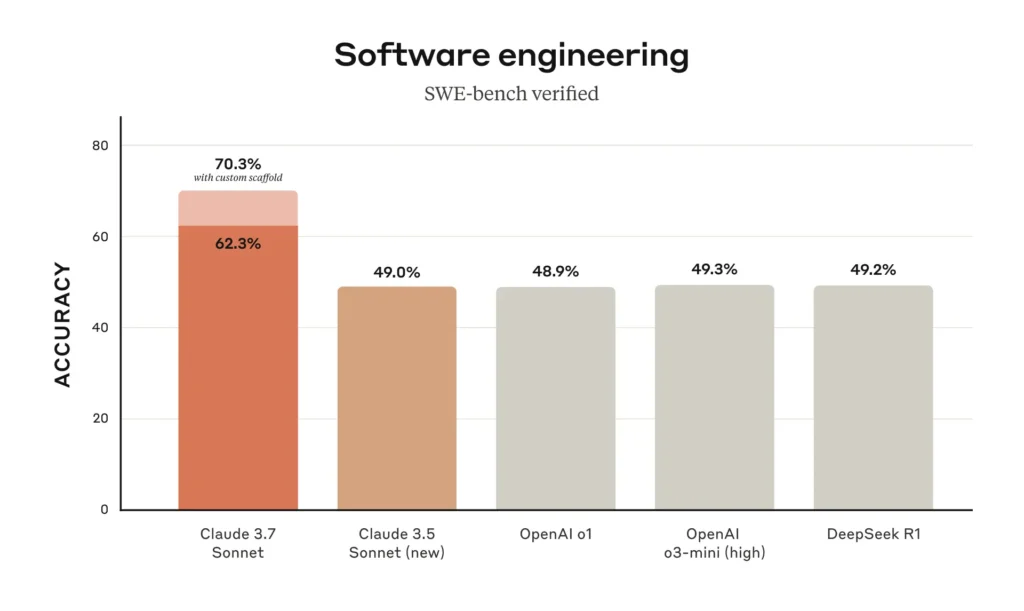
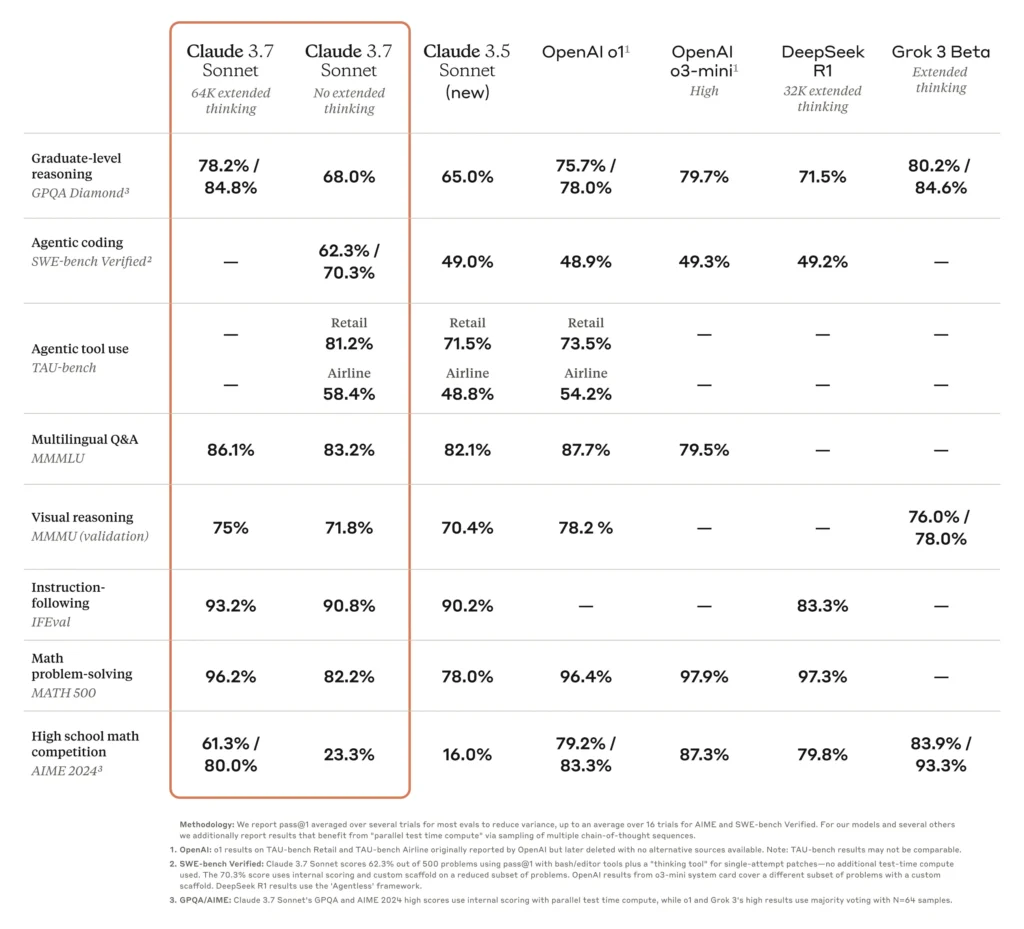
While Grok 3 from Elon Musk’s xAI dominates high school math competitions with 83.9%/93.3% on AIME 2024 (compared to Claude’s 61.3%/80.0%), Claude 3.7 Sonnet outshines in software engineering tasks with 70.3% accuracy on SWE-bench and achieves near-perfect 96.5% on physics problems.
In instruction-following (IFEval), Claude 3.7 Sonnet scores 93.2% in extended thinking mode and 90.8% in standard mode, higher than DeepSeek R1’s 83.3%. For math problem-solving (MATH 500), Claude 3.7 Sonnet with extended thinking reaches 96.2%, competitive with OpenAI models.
For science and general reasoning tasks, using parallel test-time compute on the Graduate-Level Google-Proof Q&A Benchmark (GPQA) evaluation, it hit an overall score of 84.8%, with an impressive 96.5% on the physics subset. The model shows more modest performance on high school math competition problems (AIME 2024), scoring 61.3%/80.0% compared to Grok’s 83.9%/93.3%.
[Image courtesy of Anthropic]
Claude Code: AI that writes and executes production-ready code
The new model also introduces Claude Code, a new command-line tool (in limited preview) that lets developers delegate coding tasks to the AI directly from their terminal. With Claude Code, the model can search and edit files, write code and execute commands under human oversight.
Early testing by partner companies found Claude 3.7 to be “best-in-class” for real-world coding tasks — handling complex codebases, full-stack updates, and tool use better than other models. According to an Anthropic blog, the model consistently produces production-ready code with fewer errors and superior design than prior Claude versions.
This autonomous capability represents a significant evolution beyond simply answering questions. The mode enables the AI to work independently on multi-step tasks including writing and running code.
[Image courtesy of Anthropic]
Technical capabilities, safety improvements and pricing
Like its predecessor, Claude 3.7 supports a large context window (100K+ tokens), though this trails rivals such as some versions of Google’s Gemini, which in some configurations can accept just over 2 million tokens. The model also demonstrates multimodal capabilities – for example, it can parse text from images (performing basic OCR) and interpret visual data.
In terms of safety, Anthropic notes that Claude 3.7 can make sophisticated distinctions between allowed and disallowed requests, resulting in 45% fewer unnecessary refusals (in essence, rejecting a harmless request over safety reasons) compared to the previous model (Claude 3.7 Sonnet and Claude Code \ Anthropic). Anthropic also released a new system card detailing Claude 3.7’s safety evaluations and how the model was trained to resist issues like prompt injection.
Claude 3.7 officially launched today, replacing the previous model in Anthropic’s lineup. It is immediately accessible through Anthropic’s platforms (Claude.ai and the Anthropic API) as well as partner services like Amazon Bedrock and Google Cloud’s Vertex AI.


